In diesem Kapitel möchte ich beschreiben wie man Dateien mit Python verarbeiten kann. Bisher haben wir nur Variablen verwendet, diese verlieren jedoch ihre Gültigkeit beim Beenden oder beim Abbruch des Programmes und somit sind alle Daten verloren. Hier können wir nun eine Datei verwenden, um diese Daten zu speichern.
Eine Datei kann uns später dazu dienen Daten abzulegen welche nach einem Beenden oder eines Abbruchs des Programmes erhalten bleiben sollen.
Dateien öffnen
Um eine Datei zu öffnen, benötigen wir die Funktion „open(<<Dateiname>>,<<Modus>>)“
Dateiname
Der Dateiname ist der Name der Datei welche gelesen oder erstellt werden soll, sollte diese Datei nicht im gleichen Ordner liegen wie auch der Quellcode so muss der Pfad bis zu dieser Datei benannt werden.
Navigieren im Ordnerpfad
Sollte diese Datei nicht im selben Ordner liegen wie unser Quellcode so müssen wir eine Ebene nach oben navigieren, dieses machen wir in dem ein zwei Punkte und ein Backslash vor den Dateinamen gestellt wird. „..\“
file = open("..\beispieldatei.txt", "r")

Python – Dateiverarbeitung, Ordnerstruktur
Modus
Um zu steuern, wie diese Datei behandelt werden soll, übergibt man der Funktion „open“ einen Modus.
Mögliche Übergabewerte sind:
- „r“ – (read) lesen der Datei
- „w“ – (write) schreiben in der Datei
- „a“ – (append) hinzufügen von Dateien an das Ende der Datei
- „r+“ – spezieller Modus zum schreiben und lesen der Datei
lesen von Dateien
Fangen wir mit dem einfachen Lesen einer Textdatei an. Unsere Beispieldatei enthält 3 Zeilen.
Hallo Welt! Ich bin die zweite Zeile. Und hier kommt die dritte und letzte Zeile
Zum lesen einer Datei benötigen wir die Funktion „open“ mit dem Modus „r“.
# öffnen der Datei "Beispieldatei.txt"
# im Modus lesen ("read")
datei = open("beispieldatei.txt", "r")
# für jede Zeile in der Datei mache...
for zeile in datei:
# Ausgeben der Zeile
print(zeile)
Die Ausgabe sieht dann wie folgt aus:
Hallo Welt! Ich bin die zweite Zeile. Und hier kommt die dritte und letzte Zeile
Warum wird jeweils eine zusätzliche Leerzeile eingefügt?
Die Funktion „print“ gibt einen String aus und erzeugt am Ende der Zeile einen Zeilenumbruch.
Jedoch haben wir in unserem Text am Zeilenende auch einen Zeilenumbruch. Dieses ist ein spezielles ASCII-Zeichen, welches nicht sichtbar ist.
Nutzt man den Editor Notepad++, so kann man diese sichtbar machen.
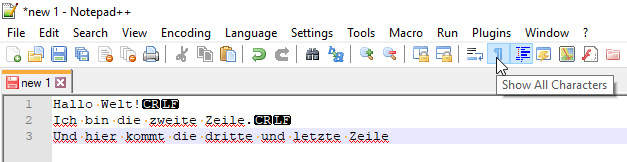
Wir sehen also nun zwei Sonderzeichen, einmal „CR“ + „LF“. Das Kürzel „CR“ steht für Carriage Return, und „LF“ steht für „Line feed“. Diese Bezeichnungen stammen noch aus der Zeit der Schreibmaschine und haben sich bis heute gehalten.
Wir können diese Zeilen auch in den Text selber implementieren, dieses geschieht, indem wir ein Backslash und ein „n“ für „NewLine“ einfügen „\n“.
text = "Hallo dies ist ein Test.\nUnd hier steht die zweite Zeile." print(text)
Entfernen der unnötigen Zeile
Wie werden wir also nun die unnötige Leerzeile los? Hierzu nutzen wir die Funktion „strip()“ welche uns das String-Objekt mitliefert.
Die Funktion „strip“ entfernt alle unsichtbaren Zeichen am Anfang und am Ende einer Zeichenkette.
Original
# Beispieltext mit
# einem Zeilenumbruch und einem Tabulator am Anfang, sowie
# einem Tabulator , sowie ein Zeilenumbruch am Ende
text = "\n\tHallo dies ist ein Test.\nUnd hier steht die zweite Zeile.\t\n"
print(text)
print("----------------------")
# Nun entfernen wir alle nicht sichtbaren Steuerzeichen am Anfang und am Ende.
# Der Zeilenumbruch in der mitte des Textes bleibt erhalten.
print(text.strip())
Die Ausgabe:
Hallo dies ist ein Test. Und hier steht die zweite Zeile. ---------------------- Hallo dies ist ein Test. Und hier steht die zweite Zeile.
Hier nun der Quellcode wie wir eine Zeile aus einer Datei lesen ohne die unsichtbaren Steuerzeichen:
datei = open("beispieldatei.txt", "r")
for zeile in datei:
print(zeile.strip())
Die Ausgabe ist nun:
Hallo Welt! Ich bin die zweite Zeile. Und hier kommt die dritte und letzte Zeile
Dateien schreiben
Wir haben zuerst die Datei zum Lesen geöffnet, nun möchten wir diese zum Schreiben öffnen.
# Datei "beispieldatei.txt" fuer den Schreibvorgang oeffnen
datei = open("beispieldatei.txt", "w")
# Den Text "Hallo Welt!" in die Datei schreiben
datei.write("Hallo Welt")
# speichern und schliessen
datei.close()
Wenn die Datei nicht existiert so wird, diese angelegt, ansonsten wird diese für das Schreiben geöffnet. Sobald diese Datei geöffnet wird (im Modus „schreiben“) werden alle Daten innerhalb der Datei gelöscht und das ohne Rückfragen.
eine Liste in eine Datei schreiben
Nun wollen wir eine Liste mit Namen in die Datei schreiben. Das Thema Listen habe ich bereits im Kapitel Python #3: Listen behandelt, des Weiteren benötigen wir eine For Schleife. (Auch die Schleifen habe ich bereits behandelt siehe Python #7: Schleifen.)
namen = ["Stefan", "Moritz", "Lutz", "Horst"]
datei = open("namen_storage.txt", "w")
for name in namen:
datei.write(name)
datei.close()
Wir haben nun die Namen erfolgreich in die Datei „namen_storage.txt“ geschrieben. Jedoch werden diese in einer Zeile hintereinander weg in der ersten Zeile geschrieben.
StefanMoritzLutzHorst
Nun wollen wir jeden Namen in einer separaten Zeile schreiben. Dazu nutzen wir, das nicht sichtbare Steuerzeichen für einen Zeilenumbruch („\n“).
namen = ["Stefan", "Moritz", "Lutz", "Horst"]
datei = open("namen_storage.txt", "w")
for name in namen:
datei.write(name)
datei.write("\n")
datei.close()
Die Ausgabe in der Datei ist nun:
Stefan Moritz Lutz Horst
hinzufügen von neuen Daten
Mit dem Modus „w“ überschreiben wir immer die Daten in der Datei. Wollen wir jedoch die alten Daten erhalten und „nur“ neue hinzufügen, so müssen wir im Modus „a“ (dieses steht für append) arbeiten.
# Bibliothek zum erzeugen von Zufallszahlen
import random
# öffnen der Datei "zufallszahlen.txt" im Modus append
datei = open("zufallszahlen.txt", "a")
# erzeugen einer Zufallszahl von 0 bis 100
zahl = random.randint(0,100)
# umwandeln der Zahl in ein String und schreiben in die Datei
datei.write(str(zahl))
# hinzufügen einer neuen Zeile
datei.write("\n")
# speichern und schließen
datei.close()
Nun schreiben wir immer wieder neue Zufallszahlen in die Datei „zufallszahlen.txt“.
Fehlerbehandlung
Wenn man eine Datei öffnet muss diese auch immer geschlossen werden, denn sonst werden die geschriebenen Daten nicht gespeichert.
datei1 = open("beispieldatei.txt", "w")
datei1.write("Hallo Welt!\n")
datei1.write("Hier kommt die zweite Zeile")
# datei1.close()
datei2 = open("beispieldatei.txt", "r")
for zeile in datei2:
print(zeile.strip()
Es erfolgt keine Ausgabe im zweiten Abschnitt des Quellcodes, da im ersten Abschnitt das „close()“ vergessen wurde. (Ist auskommentiert.)
Das Stück Quellcode ist noch sehr übersichtlich, bei größeren Skripten liegen meist zwischen diesen Abschnitten mehrere Zeilen.
Auch wird bei einem auftretenden Fehler die Funktion close nicht aufgerufen.
datei1 = open("beispieldatei.txt", "w")
datei1.write("Hallo Welt!\n")
datei1.write("Stefan ist"+38+" Jahre alt!")
datei1.close()
Dieser Quellcode erzeugt in der dritten Zeile einen Fehler, da nur Strings miteinander konkateniert werden kann.
Traceback (most recent call last):
File "C:\temp\HelloWorld\src\hello.py", line 3, in <module>
datei1.write("Stefan ist"+38+" Jahre alt!")
TypeError: can only concatenate str (not "int") to str
Wie kann man sicherstellen das die Datei geschlossen wird?
Diese Frage ist wohl berechtigt, denn ein Fehler kann immer auftreten, ob nun von außen oder von innen.
Hier nutzen wir das Schlüsselwort „with“.
with open("beispieldatei_with.txt", "w") as datei:
datei.write("Hallo Welt!")
text = "a"+1
datei.write("Hier kommt die zweite Zeile!")
In dem Stück Quellcode provoziere ich den gleichen Fehler, jedoch wird in diesem Fall die Zeile „Hallo Welt!“ gespeichert.
Arbeiten mit CVS Dateien
Eine CSV Datei ist eine Textdatei, in welche die Daten ähnlich wie eine Tabelle abgelegt werden können, d.h. man besitzt Zeilen und Spalten. Eine Spalte wird dabei durch einen Separator gekennzeichnet. Als Separator kann jedes beliebige Zeichen dienen, jedoch hat sich „eingebürgert“ das ein Semikolon genutzt wird.
Legen wir uns für das nächste Beispiel eine kleine Liste mit Name, Alter und Geschlecht an. Als Separator verwende ich ein Semikolon.
Stefan;38;männlich Melanie;23;weiblich Lutz;56;männlich
Man sieht, es kann Text und Zahl gemischt werden, jedoch ist es nicht von Vorteil den Separator im Text zu verwenden, denn an diesem Zeichen wollen wir später unseren String splitten.
# öffnen der Datei "namen.csv" zum lesen
with open("namen.csv","r") as datei:
# für jede Zeile in der Datei...
for name in datei:
# entfernen der nicht sichtbaren sowie Leerzeichen am Anfang und am Ende der Zeile, sowie
# teilen der Zeile in ein Liste, die Werte werden jeweils vor einem Semikolon getrennt
zeile = name.strip().split(";")
# erster Eintrag (Index 0) aus der Liste repräsentiert den Namen
vorname = zeile[0]
# zweiter Eintrag (Index 1) aus der Liste repräsentiert das Alter
alter = zeile[1]
# dritter Eintrag (Index 2) aus der Liste repräsentiert das Geschlecht
geschlecht = zeile[2]
# Ausgabe der Werte in einem Satz.
print(vorname,"ist",geschlecht, "und", alter, "Jahre alt.", sep=" ")
Als Ausgabe erhalten wir dann:
Stefan ist männlich und 38 Jahre alt. Melanie ist weiblich und 23 Jahre alt. Lutz ist männlich und 56 Jahre alt.
Filtern
In dem Kapiteln Python #6: Bedingte Anweisungen sowie Python #7: Schleifen habe ich die Befehle if, elif sowie continue vorgestellt welche wir nun nutzen möchten, um die CSV Datei nach einem Wert zu filtern.
Nehmen wir an, wir wollen alle männlichen Personen aus dieser Liste ausgegeben haben:
with open("namen.csv","r") as datei:
for name in datei:
zeile = name.strip().split(";")
vorname = zeile[0]
alter = zeile[1]
geschlecht = zeile[2]
# prüfen ob das Geschlecht ungleich "männlich" ist,
# wenn dieses so ist, dann soll die for - Schleife an
# dieser Stelle unterbrochen werden und mit dem nächsten
# Datensatz fortgeführt werden
if geschlecht != "maennlich":
continue
print(vorname,"ist",geschlecht, "und", alter, "Jahre alt.", sep=" ")
Die Ausgabe ist nun:
Stefan ist maennlich und 38 Jahre alt. Lutz ist maennlich und 56 Jahre alt.
Möchte man jedoch nach dem Alter (also einer Zahl) filtern so muss man bedenken das alle Werte in der erzeugten Liste Strings sind.
['Stefan', '38', 'maennlich'] ['Melanie', '23', 'weiblich'] ['Lutz', '56', 'maennlich']
Dieses erkennt man daran, dass die Werte in Anführungszeichen gesetzt sind.
Also müssen wir den Wert erst in eine Zahl umwandeln.
alter = int(zeile[1])
Um dann diese Zahl auf den gewünschten Wert zu prüfen:
with open("namen.csv","r") as datei:
for name in datei:
zeile = name.strip().split(";")
vorname = zeile[0]
alter = int(zeile[1])
geschlecht = zeile[2]
if alter <= 48:
continue
print(vorname,"ist",geschlecht, "und", alter, "Jahre alt.", sep=" ")
Nun geben wir nur die Personen aus, bei welchen das Alter größer als 48 Jahre ist.
Erstellen einer CSV Datei per Script
Nachdem wir mit einer bestehenden CSV Datei gearbeitet haben wollen wir uns eine solche Datei aus einer Mehrdimensionalen Lister erzeugen. Das Thema Listen habe ich bereits im Kapitel Python #3: Listen ausgiebig behandelt.
personen = [["Stefan", 38, "maennlich"],
["Melanie", 23, "weiblich"],
["Lutz", 56, "maennlich"]]
with open("personen.csv","w") as datei:
for person in personen:
name = person[0]
alter = person[1]
geschlecht = person[2]
datei.write(name+";"+str(alter)+";"+geschlecht+"\n")
with open("personen.csv","r") as datei:
for name in datei:
zeile = name.strip().split(";")
vorname = zeile[0]
alter = int(zeile[1])
geschlecht = zeile[2]
print(vorname,"ist",geschlecht, "und", alter, "Jahre alt.", sep=" ")
Im ersten Abschnitt habe ich eine mehrdimensionale Liste mit 3 Personen erstellt. Um im zweiten Abschnitt diese Liste in eine CSV Datei zu speichern.
Ich habe die Werte in extra Variablen ausgelagert, dieses erhöht die Lesbarkeit des Quellcodes erheblich.
Man könnte jedoch auch schreiben:
datei.write(person[0]+";"+str(person[1])+";"+person[2]+"\n")
Jedoch muss man den Wert für das Alter in ein String umwandeln, da die String-Konkatenation ausschließlich mit Strings funktioniert.
Im dritten und letzten Abschnitt gebe ich diese Liste aus.
Die Ausgabe:
Stefan ist maennlich und 38 Jahre alt. Melanie ist weiblich und 23 Jahre alt. Lutz ist maennlich und 56 Jahre alt.
Letzte Aktualisierung am: 01. Mai 2023
