Mit der Skriptsprache Python3 kann man sich relativ simple und schnell einen Crawler für Meta-Daten einer Webseite erstellen. Und in diesem Beitrag möchte ich dir gerne zeigen wie du dir deinen eigenen Crawler erstellen kannst.
Vorwort
Da ich die SEO Werte für meinen Blog im Blick haben möchte verwende ich so einige Tools welche mir die Arbeit etwas erleichtern. Zu diesen Tools gehört unter anderem ubersuggest von Neil Patel. Mit diesem Tool kann man einen Seiten Audit erstellen lassen und erhält eine Liste mit Vorschlägen zur Verbesserung der SEO Werte. Es werden in der kostenfreien Version nicht alle Verbesserungsvorschläge angezeigt, dieses kann ich verstehen denn auch dieser Herr möchte von etwas leben und hat sehr viel in dieses Tool investiert und möchte natürlich seine Arbeit bezahlt haben wollen.
Ausblick
In diesem ersten Teil möchte ich aufzeigen wie ich die Meta-Daten meines Blogs auslese. Ein großes Problem bei den Webcrawlern ist es, dass die zunächst gelesen und dann ausgewertet werden muss. D.h. eine Portierung auf andere Seiten ist manchmal sehr schwierig bzw. mit sehr viel arbeit verbunden.
Was sind Meta-Daten?
Als Meta-Daten zu einer Webseite bezeichnet man die Daten welche eine Webseite inhaltlich beschreiben und auskunft über den Author und die Keywords / Schlüsselwörter geben. Diese Daten werden von Suchmaschinen aufgenommen und in einen Index sortiert abgelegt.
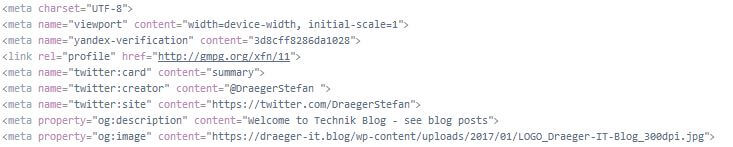
Programmieren eines Crawlers
Wollen wir nun damit anfangen unseren Crawler zu programmieren.
Als Entwicklungsumgebung verwende ich Anaconda, dieses mächtige Tool bringt bereits alles mit und somit können wir nach der Installation von Anaconda gleich loslegen mit der Programmierung.
Schritt 1 – lesen der Webseite
In diesem Beispiel möchte ich meinen Blog analysieren, d.h. wir starten mit der Adresse https://draeger-it.blog.
Wenn wir diese Seite im Browser aufrufen, wird der HTML, JavaScript, Bilder und Videos geladen und dargestellt (d.h. geladen, geparst und gerendert).
laden des Inhalts
In diesem Schritt laden wir auch den Inhalt jedoch wollen wir diesen Inhalt „nur“ parsen und wollen diesen selber auswerten.
Zum laden der Daten (des sogenannten HTML Contents) verwenden wir die Bibliothek Requests welche mit Anaconda bereits installiert wurde.
import requests
req = requests.get('https://draeger-it.blog')
# den HTTP - Status Code ausgeben
# Wenn alles i.O. ist, erhält man den Status Code 200 zurück.
print(req.status_code)
# der HTML Conent der Seite
print(req.content)
Mit dem Befehl „import“ geben wir an das wir die Bibliothek „requests“ laden. Danach setzen wir einen Request mit der Funktion „get“ und der Adresse „https://draeger-it.blog“ ab und erhalten ein komplexes Requests Objekt zurück.
Dieses Requests Objekt enthält unter anderem den Status Code sowie den Content.
Eine Liste an gültigen HTTP Status Codes findest du in dem Wikipedia Artikel „HTTP-Statuscode“ unter
Seite „HTTP-Statuscode“. In: Wikipedia, Die freie Enzyklopädie. Bearbeitungsstand: 28. Februar 2020, 09:34 UTC. URL: https://de.wikipedia.org/w/index.php?title=HTTP-Statuscode&oldid=197248847 (Abgerufen: 8. April 2020, 12:37 UTC)
Möchtest du dir alle Daten des Requests Objekt ausgeben lassen, so kannst du dieses mit
print(req.__dict__)
machen.
HTML Content
Bevor wir uns mit der Verarbeitung der HTML Struktur befassen, schauen wir uns zunächst ein kleines Konstrukt an:
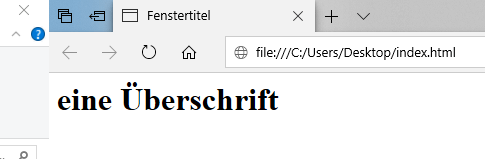
<html>
<head>
<meta name= "description" content="Hallo Welt!"></meta>
<title>Fenstertitel</title>
</head>
<body>
<h1>eine Überschrift</h1>
</body>
</html>
Dieser kleine HTML Content zeigt auf der Seite eine Überschrift „eine Überschrift“ an und im Reiter des Browsers „Fenstertitel“ an.
parsen der HTML Struktur
Nachdem wir nun den HTML Content erfolgreich geladen haben, wollen wir diesen maschinell einlesen und verarbeiten, dieser Vorgang wird parsen genannt. Für diese Aufgabe verwenden wir eine weitere Bibliothek welche sich BeautifulSoup nennt und wie Requests bereits mit Anaconda installiert wurde.
import requests
from bs4 import BeautifulSoup
req = requests.get("https://draeger-it.blog")
beautifulSoup = BeautifulSoup(req.content, "html.parser")
Wir können nun mit verschiedenen Funktionen Elemente in dem HTML Content suchen bzw. zu einer Liste zusammenfassen und verarbeiten.
Bevor wir nun ein komplexes HTML Dokument (wie es die Seite https://draeger-it.blog bietet) parsen, wollen wir mit einem kleinen Beispiel anfangen.
Unter nachfolgendem Link findest du einen komprimierten Ordner mit einer kleinen Webseite. Diese Seite enthält einige Meta-Tags, Bilder und Texte (Überschriften, Absätze) und natürlich für das Styling einiges an CSS.
Die Zipdatei kannst du in einem beliebigen Ordner entpacken jedoch empfehle ich dir diese in das Projektverzeichnis deines Python3 Projektes zu entpacken.
exkurs laden von Dateiinhalten
Da der HTML Content nun aus einer Datei und nicht aus dem Internet geladen werden benötigen wir eine Funktion welche den Inhalt einer Datei einliest und uns zurück liefert.
Wie man eine Datei in Python3 verarbeitet habe ich bereits im Beitrag Python #10: Dateiverarbeitung erläutert. Möchte hier jedoch daran anknüpfen.
Der Funktion „readHtmlFile“ wird als Parameter der absolute Pfad zur Datei angegeben, bzw. ein relativer Pfad ausgehend vom Speicherort des Python3 Skriptes. Es wird danach eine Variable angelegt um später in einer Schleife, jede einzelne Zeile aus der Datei zu lesen, den Zeilenumbruch zu entfernen und in der Variable „htmlContent“ abzulegen.
Am Schluß wird die Variable „htmlContent“ zurück geliefert.
def readHtmlFile(file):
htmlContent = ""
with open(file, "r") as htmlFile:
htmlContent = htmlFile.read().replace('\n', '')
return htmlContent
Schritt 2 – parsen / filtern der Webseite
Im ersten Schritt habe ich dir gezeigt wie du Daten von einer Internetseite bzw. aus einer Datei laden kannst. Diese Daten wollen wir nun mit BeautifulSoup verarbeiten.
Ein großer Vorteil ist, das wir den HTML Baum nicht unbedingt kennen müssen um an die gewünschten HTML Tags zu gelangen.
Zunächst wollen wir, wie bereits erwähnt eine einfache HTML Seite verarbeiten. Den Downloadlink zu dieser Seite findest du etwas weiter oben.
Ausgeben aller Überschriften
Zunächst wollen wir alle Überschriften aus dem HTML Dokument auf der Konsole ausgeben.
Mit der Funktion „find_all“ holen wir uns eine List mit allen HTML Elemente welche zu dem angegebenen Tag passen.
from bs4 import BeautifulSoup
def readHtmlFile(file):
htmlContent = ""
with open(file, "r") as htmlFile:
htmlContent = htmlFile.read().replace('\n', '')
return htmlContent
htmlContent = readHtmlFile('./testhtml/sample.html')
beautifulSoup = BeautifulSoup(htmlContent, "html.parser")
for ue in beautifulSoup.find_all('h1'):
print(ue)
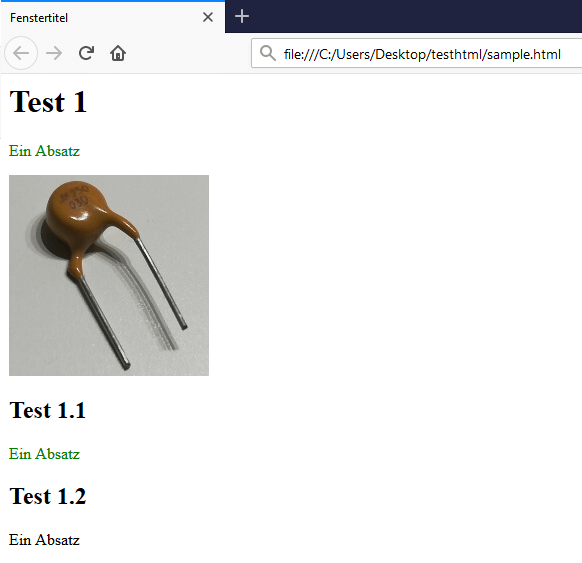
In diesem Beispiel gebe ich die HTML Tag samt dem Inhalt auf der Konsole aus und erhalte folgende Ausgabe:
<h1>Test 1</h1> <h1>Test 2</h1> <h1>Test 3</h1>
Möchten wir nur den Inhalt des HTML Tags haben so können wir mit der Funktion „ue.text“ den Inhalt holen.
for ue in beautifulSoup.find_all('h1'):
print(ue.text)
Test 1
Test 2
Test 3
Diese Funktion bietet auf jedem HTML Element den Text zwischen dem öffnenden und schließenden Element an. D.h. es passt auch für div, span, p usw.
Möchte man nur das erste Element aus dem HTML Content haben wollen so kann man die Funktion „select_one“ benutzen.
print(beautifulSoup.select_one('h1').text)
Wichtig dabei ist jedoch das geprüft wird dass, ein Element gefunden wurde und nicht mit einem NoneType „gearbeitet“ wird.
tag = beautifulSoup.select_one('h1')
if tag is not None:
print (tag.text)
Ausgeben aller Absätze mit der CSS Klasse
Wir können nun auch bestimmte HTML Tags filtern welche ein Attribut mit einem bestimmten Wert haben.
for tag in beautifulSoup.select('p[class*="clss1"]'):
print (tag.text)
Schritt 3 – lesen der Meta Tags
Die Meta Tags welche uns zunächst interessieren haben folgende Attribute, Werte und Formate.
| Attribut | Wert | Format |
|---|---|---|
| name | author | String |
| name | description | String |
| property | og:locale | String |
| property | article:tag | Liste |
| property | og:title | String |
| property | article:published_time | Datum / Zeitstempel mit Zeitzone |
| property | article:modified_time | Datum / Zeitstempel mit Zeitzone |
Wir können, wenn der HTML Tag gefunden wurde auf die Attribute wie in einer Liste zugreifen:
for tag in beautifulSoup.select('meta'):
if tag['name'] == 'author':
print(tag['content'])
Jedoch haben wir ein Problem wenn dieses Attribut NICHT existiert somit müssen wir auch hier einen zusätzlichen Check einfügen damit unser Skript sauber läuft.
for tag in beautifulSoup.select('meta'):
if tag.get("name", None) == "author":
print(tag.get("content", None))
Die Funktion „get“ auf dem HTML Tag kann optional einen Parameter enthalten welcher zurück gegeben werden soll, wenn das Attribut nicht gefunden wurde. In diesem Fall geben wir None zurück.
from bs4 import BeautifulSoup
def readHtmlFile(file):
htmlContent = ""
with open(file, "r") as htmlFile:
htmlContent = htmlFile.read().replace('\n', '')
return htmlContent
def printMetaContent(attributName, attributWert):
if tag.get(attributName, None) == attributWert:
print(tag.get("content", None))
htmlContent = readHtmlFile('./testhtml/sample.html')
beautifulSoup = BeautifulSoup(htmlContent, "html.parser")
for tag in beautifulSoup.select('meta'):
printMetaContent('name', 'author')
printMetaContent('name', 'description')
printMetaContent('property', 'og:locale')
printMetaContent('property', 'og:title')
printMetaContent('property', 'article:published_time')
printMetaContent('property', 'article:modified_time')
Für mehr Übersicht im Quellcode habe ich den Code für das prüfen des HTML Tags in eine eigene Funktion ausgelagert und übergebe nur die beiden Parameter zur Prüfung.
Das Ergebnis sind nun unsere Daten aus den Meta-Tags der HTML Seite.
Max Mustermann Eine einfache Seitenbeschreibung welche in der Google Sucher erscheinen würde. de_DE Dieser Titel würde in einem sozialen Netzwerk stehen! 2020-04-07T17:43:26+00:00 2020-04-07T17:52:31+00:00
Das der Text nicht korrekt encoded ist liegt unter anderem daran das wir die Daten aus einer Datei laden. Wenn man jedoch von einer Seite den Inhalt läd, werden die Umlaute korrekt angezeigt.
from bs4 import BeautifulSoup
import requests
def printMetaContent(attributName, attributWert):
if tag.get(attributName, None) == attributWert:
print(attributWert,': ',tag.get("content", None))
req = requests.get("https://draeger-it.blog/arduino-lektion-92-kapazitiver-touch-sensor-test-mit-einer-aluminiumplatte/")
beautifulSoup = BeautifulSoup(req.content, "html.parser")
for tag in beautifulSoup.select('meta'):
printMetaContent('name', 'author')
printMetaContent('name', 'description')
printMetaContent('property', 'og:locale')
printMetaContent('property', 'og:title')
printMetaContent('property', 'article:published_time')
printMetaContent('property', 'article:modified_time')
Ausblick auf den zweiten Teil
Im zweiten Teil werden wir die Daten nach den allg. gültigen „SEO Richtlinien“ von Google auswerten und in eine Datei speichern. Zuerst werden wir die Daten Kommasepariert in eine CSV Datei speichern und danach werde ich zeigen wie man die Daten in ein Microsoft Excel Dokument (*.xlsx) speichert.
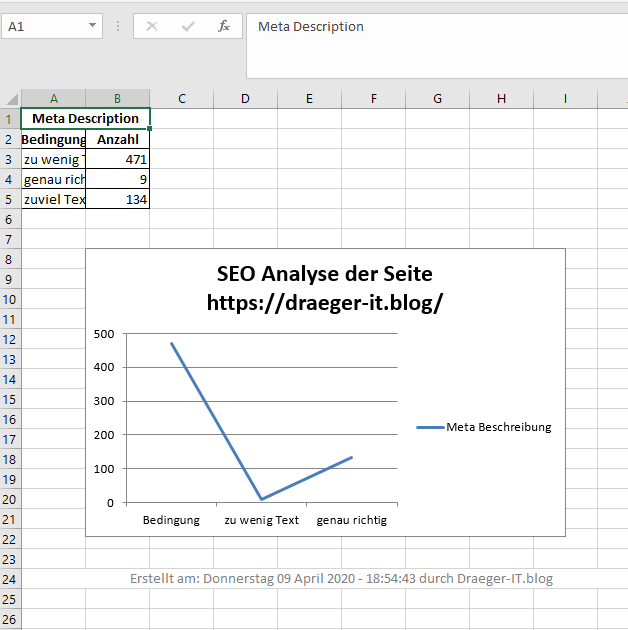
Die Ablage in ein Excel Dokument hat den Vorteil, dass eine gesonderte Prüfung auf das Trennzeichen der CSV Datei entfällt. Und wir können aus den gesammelten Daten Diagramme erstellen, um noch schneller einen Überblick zu bekommen.
Letzte Aktualisierung am: 03. Mai 2023

1 thought on “Crawler für Webseite mit Python3 Programmieren – Teil 1 – Meta Daten auslesen”