In diesem Beitrag möchte ich dir die Generator in Python3 vorstellen. Mit Generatoren können Datenstrukturen „Stück für Stück“ durchlaufen werden, jedoch anders als mit einer normalen For-Schleife. Nehmen wir zunächst eine Liste von drei Personen, diese können wir mit einer einfachen For-Schleife durchlaufen und auf der Konsole ausgeben.
personen = [['Max','Mustermann', 31], ['Jochen', 'Meier', 45], ['Birgit', 'Mueller', 56]]
for vorname, nachname, alter in personen:
print('Vorname: ', vorname)
print('Nachname: ', nachname)
print('Alter: ', str(alter))
print('-----------------------------')
Die Ausgabe auf der Konsole wäre dann folgende:
Vorname: Max Nachname: Mustermann Alter: 31 ----------------------------- Vorname: Jochen Nachname: Meier Alter: 45 ----------------------------- Vorname: Birgit Nachname: Mueller Alter: 56 -----------------------------
Implementation eines Generators
Ein Generator ist eine Funktion welche ein Element aus einer Datenstruktur liefert. Dazu nutzt man das Schlüsselwort „yield“.
Zunächst definieren wir eine Funktion in welcher wir nacheinander die Werte (Personen) aus der bereits bekannten Liste zurückliefert.
personen = [['Max','Mustermann', 31], ['Jochen', 'Meier', 45], ['Birgit', 'Mueller', 56]]
def gen_person():
yield personen[0]
yield personen[1]
yield personen[2]
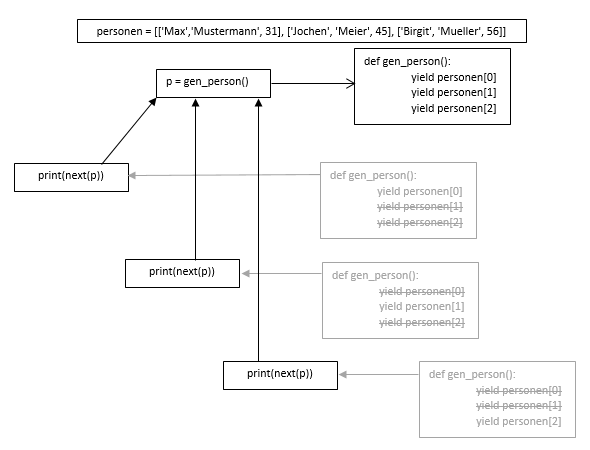
Nun kann man diese Werte jeweils mit der Funktion „next“ aus dem Generator-Objekt „Stück-für-Stück“ lesen.
p = gen_person() print(next(p)) print(next(p)) print(next(p))
Wir erhalten auf der Konsole die Ausgabe der Liste.
['Max', 'Mustermann', 31] ['Jochen', 'Meier', 45] ['Birgit', 'Mueller', 56]
Alternativ könnte man nun die Daten mit einer For-Schleife wie folgt laden.
personen = [['Max','Mustermann', 31], ['Jochen', 'Meier', 45], ['Birgit', 'Mueller', 56]]
def gen_person():
yield personen[0]
yield personen[1]
yield personen[2]
p = gen_person()
for i in range(0,len(personen)):
print(personen[i])
Wie arbeitet das dargestellte Konstrukt?
Ein Generator bietet eine Art Iterator / Liste als Rückgabewert an, jedoch immer nur ein Stück aus dieser Liste. Das können wir uns wiefolgt vorstellen als das die Generatorfunktion immer nur ein Stück liefert, sich die Position merkt und beim nächsten betreten der Funktion an dem darauffolgenden Index fortsetzt.
Wenn wir diese Liste mit den Personen mit einem Generator durchlaufen dann wird die Liste „Stück für Stück“ abgearbeitet.
personen = [['Max','Mustermann', 31], ['Jochen', 'Meier', 45], ['Birgit', 'Mueller', 56]]
def gen_person():
for person in personen:
print('Funktion gen_person()')
yield person
for vorname, nachname, alter in gen_person():
print('For-Schleife')
print('Vorname: ', vorname)
print('Nachname: ', nachname)
print('Alter: ', str(alter))
print('-----------------------------')
Auf der Konsole sieht man,
- das zunächst die Funktion „gen_person“ aufgerufen,
- die For-Schleife mit dem Datensatz abgearbeitet,
- danach die Funktion „gen_person“ an der nächsten Stelle in der Liste fortgeführt
wird.
Der Vorteil eines Generators wird bei einer so kleinen Liste nicht sofort erkennbar aber wenn man eine sehr große Datenstruktur wie eine CSV Datei durchlaufen möchte sieht man es sofort. Eine solche große CSV Datei findest du zbsp. von der GeoIP Datenbank. Die verlinkte CSV Datei enthält mehr als 5,39 Millionen Zeilen und ist ca. 450MB groß.
Python ist sehr gut geeignet um große Datenmengen zu verarbeiten, daher wäre es auch sehr einfach die CSV – Datei in einem rutsch zu verarbeiten, aber wir werden im nachfolgenden die Datei „Schritt-für-Schritt“ durchlaufen.
def gen_geoIpCSV():
with open('.\data\dbip-city-lite-2020-07.csv','r', encoding="utf-8") as csvFile:
for line in csvFile:
if ",\"" not in line:
yield line.split(',')
else:
continue
for ip_start, ip_end, continent, country, stateprov, city, lat, lon in gen_geoIpCSV():
print(city.encode())
Das Problem in der CSV Datei ist dass, einige Städte in Anführungszeichen gesetzt sind, dieses liegt daran das in dem Namen der Stadt ein Komma vorkommt und gleichzeitig das Komma als CSV Separator genutzt wird. Die Werte müßten gesondert behandelt werden, jedoch wäre das für diesen Beitrag zu viel und daher überspringe ich die betroffenen Datensätze.
Letzte Aktualisierung am: 30. April 2023
