Die Stapelverarbeitung von Daten wurde mit dem JSR 352 in die Oracle Java Version 1.7 implementiert.
Grundlage dieses JSR (Java Specification Request) ist die Spring Batch Implementation. Welche ich hier gerne, etwas genauer beschreiben möchte.
Vorbedingungen
Es wird vorausgesetzt die folgende Software installiert und konfiguriert ist:
Einfaches Projekt zum verarbeiten einer CSV Datei
Ziel des Projektes
Jedes Projekt benötigt ein Ziel. Dieses Projekt soll das Ziel haben eine CSV Datei mit Daten zu lesen
und in eine andere CSV Datei zu schreiben. Später soll der CSVWriter gegen einen PDFWriter ersetzt werden. (Was deutlich mehr Sinn ergibt!)
Ablage
Dieses Projekt habe ich online, im GitHub unter https://github.com/StefanDraeger/BatchWorker abgelegt.
In den ersten Commits musste ich das Projekt auf ein Level bringen damit ich dieses in diesem Tutorial verwenden kann.
CSV Datenformat
Die Daten einer CSV Datei können mit folgendem Trenner separiert sein:
- Komma,
- Semikolon,
- Leerzeichen,
- oder andere Zeichen
Eine sehr gute erläuterung zum CSV Format ist unter https://de.wikipedia.org/wiki/CSV_(Dateiformat) zu finden.
Die Rohdaten der CSV:
1,Test1,123.4,1488459071648 2,Test2,23.4,1488459071649 3,Test3,13.4,1488459071650 4,Test4,323.4,1488459071651 5,Test5,523.4,1488459071652 6,Test6,623.4,1488459071653
- erste Spalte ist die ID (fortlaufende Nummer)
- zweite Spalte ist ein Beschreibungstext
- dritte Spalte ist ein Double Wert
- vierte Spalte ist ein Timestamp
Apache Maven
Nachdem wir ein einfaches Maven Projekt erstellt haben müssen wir nun noch die benötigten Abhängigkeiten und Plugins für das spätere compilieren und bauen in das Projekt bringen.
Dependencies
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>log4j-over-slf4j</artifactId> </dependency> </dependencies>
Plugins
<build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <version>1.5.1.RELEASE</version> <executions> <execution> <goals> <goal>repackage</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
Nachdem die Dependencies geladen wurden (eventuell mit einem mvn install nachhelfen). Kann nun mit der Implementierung begonnen werden.
Viele Wege führen nach Rom!
Frei nach dem Sprichwort „Viele Wege führen nach Rom!“ möchte ich auch die Implementierung von Spring Batch vornehmen.
Es gibt nämlich zwei Möglichkeiten dieses Framework zu verwenden. Einmal rein programmatisch und einmal mit XML Konfiguration, beide haben Ihre Vor- und Nachteile.
Im ersten Schritt möchte ich die Implementierung mit Java Quellcode erläutern, da danach die XML Konfiguration besser verstanden wird.
Was wird für die Stapelverarbeitung benötigt?
Da wir ein FatJar am Ende bauen werden, benötigen wir eine Main Klasse welche später in der Maven POM.XML konfiguriert wird.
Application.java
@SpringBootApplication
public class Application {
/**
* Startmethode der Java Anwendung
* @param args - Parameter von der Konsole
* @throws Exception
*/
public static void main(String[] args) throws Exception {
SpringApplication.run(Application.class, args);
}
}
Die Klasse Application erhält die Annotation @SpringBootApplication und führt in der main Methode sich selber aus, damit wird der SpringBootApplication prozess gestartet und eine Klasse mit der Anotation @Configuration gesucht.
BatchConfiguration.java
Die Klasse BatchConfiguration enthält wie der Name es vermuten lässt die Konfiguration (Steps usw.) für unsere Stapelverarbeitung. Durch die zuvor erwähnte Annotation @Configuration wird diese als Konfiguration herangezogen.
Die zusätzliche Annotation @EnableBatchProcessing ermöglicht es nun die Features von Spring Batch in einer Klasse zu verwenden, welche zuvor mit der Annotation @Configuration benannt wurde.
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
private static final int CHUNK_SIZE = 0;
private static final String INPUT_FILE = "./csv/data.csv";
private static final String STEP1 = "step1";
private static final String IMPORT_JOB = "convertCSVtoPdfJob";
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
private long timestamp = 0L;
@Bean
public FlatFileItemReader<SensorEntity> reader() {
timestamp = System.currentTimeMillis();
FlatFileItemReader<SensorEntity> reader = new FlatFileItemReader<SensorEntity>();
reader.setResource(new FileSystemResource(INPUT_FILE));
reader.setLineMapper(new DefaultLineMapper<SensorEntity>() {
{
setLineTokenizer(new CSVSensorTokenizer());
setFieldSetMapper(new CSVSensorFieldSetMapper());
}
});
return reader;
}
@Bean
public CustomItemProcessor processor() {
return new CustomItemProcessor();
}
@Bean
public CSVWriter writer() {
return new CSVWriter(timestamp);
}
@Bean
public Job convertCSVtoPdfJob(@Qualifier("step1") Step step1) {
return jobBuilderFactory.get(IMPORT_JOB).start(step1).build();
}
@Bean
public Step step1() {
return stepBuilderFactory.get(STEP1).<SensorEntity, SensorEntity>chunk(CHUNK_SIZE).reader(reader())
.writer(writer()).build();
}
}
In Zeile 19 bis 31 wird der Reader für die Daten beschrieben, da die Verarbeitung einer CSV Datenstruktur bereits standardmäßig implementiert ist muss hier nur die interne Struktur benannt worden, dazu wird die Klasse CSVSensorTokenizer wie folgt angelegt:
public class CSVSensorTokenizer extends DelimitedLineTokenizer {
{
setNames(new String[] { "ID", "DESCRIPTION", "VALUE","TIMESTAMP" });
}
}
Wichtig! Die Groß- undKleinschreibung der String Werte sind nicht wichtig. Es muss jedoch auf die korrekte Schreibweise geachtet werden. Die Spring Configuration durchsucht die Entity nach dem Wert Bsp. ID. Findet diese eine nach der EJB konformität implementierte Variable (getter & setter, CamelCase usw.) so wird diese verwendet. Was jedoch beim Testen aufgefallen ist, dass wenn der Wert ID123 lautet trotzdem die korrekte Variable (ID) gefunden wurde.
Es muss dann noch ein Mapping geschehen da wir für die Felder auch eine Entity benötigen:
public class CSVSensorFieldSetMapper extends BeanWrapperFieldSetMapper<SensorEntity>{
{
setTargetType(SensorEntity.class);
}
}
Die Methode
convertCSVtoPdfJob(@Qualifier("step1") Step step1)
kann um beliebig viele Steps erweitert werden.
Methode mit „nur“ einem Step
@Bean
public Job convertCSVtoPdfJob(@Qualifier("step1") Step step1) {
return jobBuilderFactory.get(IMPORT_JOB).start(step1).build();
}
Methode mit zwei aufeinanderfolgenden Steps
@Bean
public Job convertCSVtoPdfJob(@Qualifier("step1") Step step1, @Qualifier("step2") Step step2 ) {
return jobBuilderFactory.get(IMPORT_JOB).start(step1).next(step2).build();
}
SensortEntity
Die Klasse SensorEntity enthält nun die Werte für unsere CSV Datenstruktur:
public class SensorEntity {
//Vorlaufende Nummer
private long id;
//Beschreibung
private String description;
//Wert
private double value;
//Zeitstempel des Wertes
private long timestamp;
public long getId() { return id; }
public void setId(long id) { this.id = id; }
public String getDescription() { return description; }
public void setDescription(String description) { this.description = description; }
public double getValue() { return value; }
public void setValue(double value) { this.value = value; }
public long getTimestamp() { return timestamp; }
public void setTimestamp(long timestamp) { this.timestamp = timestamp; }
}
Der CSVWriter
Da ich zuerst eine einfache Verarbeitung der CSV Daten beschreiben möchte UND es dem Tutorial nichts bringt gleich auf die Frameworks iText oder Apache POI zu wechseln, implementiere ich einen einfachen CSVWriter.
public class CSVWriter implements ItemWriter<SensorEntity> {
private static final String DATETIME_FORMAT = "dd.MM.yyyy HH:mm:ss:SS";
private static final String STR_FORMAT = "%d;%s;%f;%s \r\n";
private static final String EXPORT = "export_";
private static final String CSV = ".csv";
private DateFormat dateFormat = new SimpleDateFormat(DATETIME_FORMAT);
private long timestamp = 0L;
public CSVWriter(long timestamp) {
this.timestamp = timestamp;
}
@Override
public void write(List<? extends SensorEntity> sensoreValues) throws Exception {
String filename = EXPORT.concat(String.valueOf(this.timestamp)).concat(CSV);
File file = new File(filename);
try (BufferedWriter bw = new BufferedWriter(new FileWriter(file, true))) {
for (SensorEntity s : sensoreValues) {
bw.append(getCSVLine(s));
}
bw.flush();
}
}
private CharSequence getCSVLine(SensorEntity s) {
return String.format(STR_FORMAT, s.getId(), s.getDescription(), s.getValue(),
dateFormat.format(new Date(s.getTimestamp())));
}
}
Dieser Writer öffnet eine Datei im Format „export_<<TIMESTAMP>>.csv“ wenn diese Datei nicht vorhanden ist, wird diese neu erstellt. Wenn jedoch die Datei vorhanden ist, wird diese um die Einträge aus der Liste „sensorValues“ erweitert. Dieses Vorgehen ist bei der Chunk orientierten Stapelverarbeitung wichtig. (Dazu aber später mehr.)
Der Weg über XML Konfiguration
Wie am Anfang erläutert wurde, gibt es min. 2 Wege wie man Spring Batch verwenden kann.
In diesem Abschnitt möchte ich also nun die XML Konfiguration erläutern.
Als Basis für diesen Abschnitt nutze, ich das fertige Projekt welches unter folgenden Link geladen werden kann:
Erstellen der XML Konfiguration
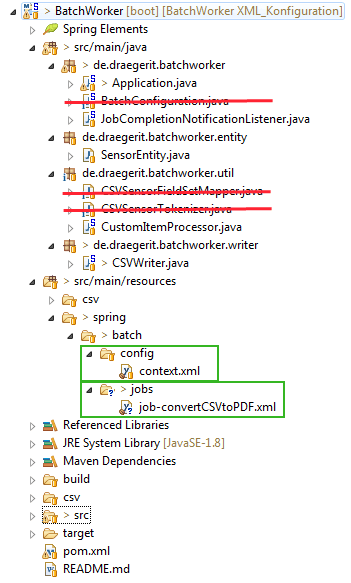
Es wird im Pfad src\main\resources\spring\batch folgende Dateien angelegt:
config\context.xml
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd">
<!-- stored job-meta in memory -->
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean">
<property name="transactionManager" ref="transactionManager" />
</bean>
<bean id="transactionManager"
class="org.springframework.batch.support.transaction.ResourcelessTransactionManager" />
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
</beans>
jobs\job-convertCSVtoPDF.xml
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:batch="http://www.springframework.org/schema/batch" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch-2.2.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.2.xsd"> <import resource="../config/context.xml" /> <bean id="sensorentity" class="de.draegerit.batchworker.entity.SensorEntity" scope="prototype" /> <batch:job id="convertCSVtoPDF"> <batch:step id="step1"> <batch:tasklet> <!-- Chunk Size --> <batch:chunk reader="csvFileReader" writer="cvsFileItemWriter" processor="customItemProcessor" commit-interval="1"> </batch:chunk> </batch:tasklet> </batch:step> </batch:job> <!-- Definieren des FileReaders --> <bean id="csvFileReader" class="org.springframework.batch.item.file.FlatFileItemReader"> <!-- Der Dateiname der zu verarbeitenden Datei --> <!-- In diesem Beispiel befindet sich die Datei im Pfad src\main\resources\csv\data.csv --> <property name="resource" value="classpath:csv/data.csv" /> <!-- In diesem Beispiel befindet sich die Datei im Pfad src\main\resources\csv\data.csv --> <!-- property name="resource" value="classpath:csv/data.csv" /--> <property name="lineMapper"> <bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper"> <property name="lineTokenizer"> <bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"> <!-- Definieren des Werte in der CSV Datei --> <property name="names" value="id,description,value,timestamp" /> </bean> </property> <property name="fieldSetMapper"> <bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"> <!-- Das Mapping auf die Entity --> <property name="prototypeBeanName" value="sensorentity" /> </bean> </property> </bean> </property> </bean> <!-- ItemProcessor für die Verarbeitung der gelesenen Items --> <bean id="customItemProcessor" class="de.draegerit.batchworker.util.CustomItemProcessor" /> <!-- Der CSVWriter für die Ausgabe --> <bean id="cvsFileItemWriter" class="de.draegerit.batchworker.writer.CSVWriter" /> </beans>
Erweitern der Klasse CSVWriter.java
Für das Erstellen der Bean CSVWriter muss ein parameterloser Konstruktor existent sein. Da wir aber im ersten Schritt einen Konstruktor erstellt haben (mit der Übergabe eines Timestamps) so ist der Default Konstruktor nicht mehr existent und muss nun eingepflegt werden.
/**
* Parameterloser Konstruktor für die XML Konfiguration
*/
public CSVWriter(){
this(System.currentTimeMillis()); //Übergabe des aktuellen Timestamps
}
Nachdem wir nun die XML Konfiguration erstellt haben können wir obsolete Klassen entfernen, das Projekt wird nun deutlich schlanker.
Chunk Orientierte Stapelverarbeitung
Ein Chunk ist ein Ergebnis aus dem Lesen eines Datensatzes (ItemReader) und der Verarbeitung (ItemProcessor), dabei wird eine Liste mit diesen verarbeiteten / auf bearbeiteten Ergebnissen gesammelt. Beim Erreichen einer maximalen Anzahl werden diese Chunks dem ItemWriter übergeben und dort persistiert. Dieses kann eine Datenbank, eine Datei oder sonst welche Schnittstellen sein. Das Minimum der Chunksize ist die positive 0 und das die positiven Integer.MAX_VALUE Zahl.
Erstellen des FatJars für die Ausführung
Damit das Projekt ohne IDE lauffähig ist, wird nun ein FatJar gebaut, dazu wird auf der Konsole folgender Befehl ausgeführt:
mvn clean install package
Nachdem der Build erfolgreich durchgelaufen ist. Dieses ist erkennbar an:
[INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 3.113 s [INFO] Finished at: 2017-03-07T20:23:49+01:00 [INFO] Final Memory: 29M/271M [INFO] ------------------------------------------------------------------------ C:\Eigene Projekte\99_Daten\02_Repo\01_Git\BatchWorker>
Befindet sich im .\target\ Verzeichnis nun das Java Archiv „BatchWorker-0.0.1-SNAPSHOT.jar“ dieses wiederum lässt sich auf der Konsole mit dem Java Befehl
java -jar BatchWorker-0.0.1-SNAPSHOT.jar
ausführen.
Jetzt haben wir aber leider nur eine Datei welche abgearbeitet werden kann und diese ist im Java Archiv gepackt. Im nächsten Schritt müssen wir also die Datei „data.csv“ nicht im Classpath suchen, sondern im Dateisystem oder viel besser als Parameter dem Job übergeben.
Übergabe des Dateinamens an den Job
Pfad relativ zum Classpath
Im ersten Schritt haben wir die Ressource an den org.springframework.batch.item.file.FlatFileItemReader statisch mit
<property name="resource" value="classpath:csv/data.csv" />
Übergeben. In diesem Fall sucht der Job die Datei im Pfad „src\main\resources“.
Absoluter Pfad
Nun möchten wir aber außerhalb des Projektes die Datei(en) ablegen, dazu könnte man nun, wie in diesem Fall auf dem Laufwerk „C“ folgende Struktur anlegen „C:\csv\daten.csv“.
<property name="resource" value="file:c:\\csv\\data.csv" />
Nun sucht die Jobkonfiguration in diesem Ordner und verarbeitet die Datei. Das ist schon deutlich dynamischer als im ersten Schritt, jedoch ist man noch auf den eindeutigen Dateinamen angewiesen.
Definition über eine Propertiesdatei
Den Dateinamen kann man auch bequem über eine Propertiesdatei konfigurieren, dazu legt man eine einfache Datei an, Bsp. „converter.properties“ mit folgendem Wert:
filename = file:C://csv//data.csv
Diese Datei muss unter „src/main/resources“ abgelegt werden und wird wiefolgt in der Jobkonfiguration, konfiguriert:
<bean class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer"> <property name="location"> <value>converter.properties</value> </property> </bean>
Nun kann in jedem Step wo diese Datei benötigt wird mit der EL „${filename}“ auf den Wert der Propertie zugriffen werden.
<!-- In diesem Beispiel befindet sich die Pfadangabe zur Datei in der Propertiesdatei -->
<property name="resource" value="${filename}" />
Es ist aber keinesfalls dynamisch, denn der Dateiname steht hier nun fest in der Propertiesdatei und kann von außen nicht so einfach geändert werden.
Übergabe als Argument
Wie man von einer Java Anwendung kennt, kann man auch hier einen (oder mehrere) Parameter übergeben.
In Eclipse kann dieses zur Entwicklungszeit über „Run -> Run Configurations….“ erledigt werden.
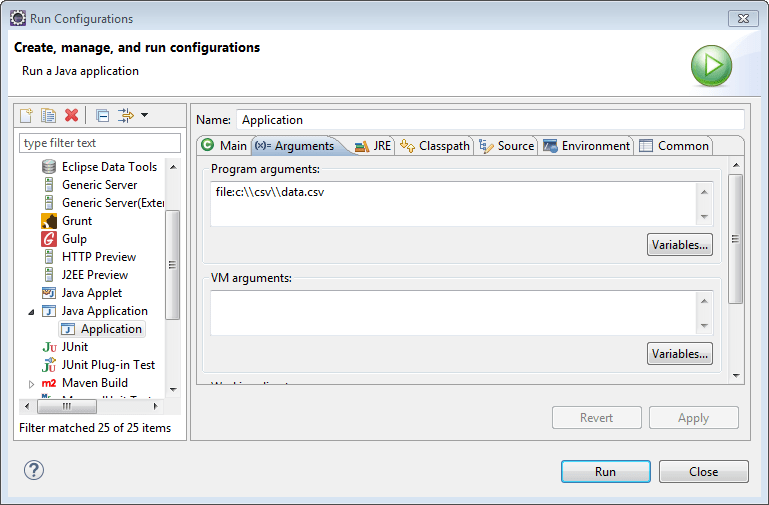
Zur Laufzeit über der Konsole wird dieses als Parameter hinter der JAR Datei angehangen:
java -jar BatchWorker-0.0.1-SNAPSHOT.jar file:c:\\csv\\data.csv
Jedoch alleine durch das vorhanden sein des Parameters wird dieser nicht verarbeitet (soviel Magie steckt nicht in Spring).
Argumente entgegennehmen
Damit wir nun den Parameter „filename“ verarbeiten können müssen wir unsere Startklasse „Application.java“ wie folgt ändern:
JobParameters params = new JobParametersBuilder().addString("filename", args[0]).toJobParameters();
JobExecution execution = jobLauncher.run(job, params);
Es wird hier mit dem JobParametersBuilder
- die Argumente entgegengenommen (Methode addString(key, value)), und
- das Objekt JobParameters erzeugt (Methode toJobParameters())
Diese Kette kann beliebig fortgesetzt werden, wichtig ist nur das am Ende die Methode toJobParameters() aufgerufen wird. (siehe Builder Pattern)
Durch den Schlüsselwert „filename“ kann nun, wie auch schon bei der Propertiesdatei mit der Expressionlanguage (EL) der Parameter geladen werden
<property name="resource" value="#{jobParameters[filename]}" />
Es ist natürlich sinnvoll eine Prüfung zu implementieren ob das Argument übergeben wurde UND ob die Datei existiert.
Das Projekt mit einer XML Konfiguration kann bequem über GitHub geladen werden.
Letzte Aktualisierung am: 26. Oktober 2022
