In der Softwareentwicklung reicht es nicht aus, nur die sogenannten Happy Cases abzudecken – also die Fälle, in denen eine Anwendung genau so funktioniert wie vorgesehen. Genauso wichtig sind die Fehlerfälle.
Ein Endpunkt auf einem Server kann vorübergehend nicht erreichbar sein, ein Gerät kann ausfallen oder eine Netzwerkverbindung kann unterbrochen werden. Solche Ausfälle können geplant oder ungeplant auftreten. Deshalb muss eine Anwendung damit umgehen können, ohne sofort komplett abzubrechen.

Node-RED ist grundsätzlich sehr robust. Es muss schon einiges passieren, damit die gesamte Anwendung beendet wird. Trotzdem kann ein einzelner Flow an einer Stelle stoppen, an der wir es nicht erwarten oder nicht möchten. Noch problematischer wird es, wenn wir gar nicht erkennen, warum der Flow nicht weiterläuft, weil keine verständliche Fehlermeldung ausgegeben wird.
In diesem Beitrag zeige ich dir deshalb, wie du Fehler in Node-RED gezielt findest und behandelst. Dabei schauen wir uns die Debug-, Catch- und Status-Node an und klären, welche Aufgabe jede dieser Nodes übernimmt.
Ein echter Fehlerfall aus der Praxis
Diesen Beitrag schreibe ich gerade während einer Zugfahrt. Dabei zeigt sich sehr deutlich, warum eine saubere Fehlerbehandlung in Node-RED wichtig ist: Die mobile Internetverbindung ist unterwegs nicht immer stabil und bricht zwischendurch vollständig ab.
Beim ersten Aufruf meines Blogs über die HTTP-Request-Node wurde die Seite noch erfolgreich geladen und der Server antwortete mit dem HTTP-Statuscode 200. Beim nächsten Versuch war die Verbindung jedoch unterbrochen und die Anfrage schlug fehl.
Damit ist dieses Beispiel kein künstlich erzeugter Testfall, sondern ein echter Anwendungsfall aus der Praxis. Netzwerkverbindungen, Server und Geräte können jederzeit vorübergehend nicht erreichbar sein. Ein guter Node-RED Flow sollte solche Situationen erkennen, den Fehler verständlich ausgeben und kontrolliert darauf reagieren.
Ausgangssituation: Ein einfacher Flow mit Fehler
Wir starten bewusst mit einem kleinen Flow:
Inject → URL setzen → HTTP Request → Debug
Beim ersten Test verwenden wir die korrekte Adresse meines Blogs. Anschließend erzeugen wir bewusst einen Fehler, indem wir den Hostnamen verändern oder die Netzwerkverbindung unterbrechen.
Node-RED Flow als JSON zum Importieren
[
{
"id": "34e4fe199e96c12e",
"type": "tab",
"label": "Flow 1",
"disabled": false,
"info": "",
"env": []
},
{
"id": "1fed1fa1c2946366",
"type": "inject",
"z": "34e4fe199e96c12e",
"name": "Anfrage an Server stellen",
"props": [],
"repeat": "",
"crontab": "",
"once": false,
"onceDelay": 0.1,
"topic": "",
"x": 190,
"y": 80,
"wires": [
[
"02edada60c105002"
]
]
},
{
"id": "02edada60c105002",
"type": "http request",
"z": "34e4fe199e96c12e",
"name": "HTTP Request",
"method": "GET",
"ret": "txt",
"paytoqs": "ignore",
"url": "https://draeger-it.blo",
"tls": "",
"persist": false,
"proxy": "",
"insecureHTTPParser": false,
"authType": "",
"senderr": false,
"headers": [],
"x": 400,
"y": 140,
"wires": [
[
"1c0dd8bbac0c8573"
]
]
},
{
"id": "1c0dd8bbac0c8573",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Ausgabe der Antwort",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 600,
"y": 200,
"wires": []
}
]
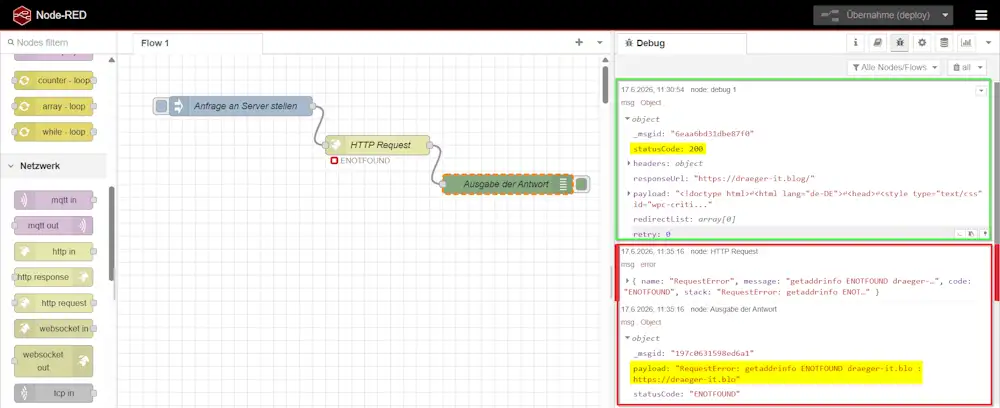
Beim Auslösen versucht die HTTP-Request-Node, die Webseite aufzurufen. Beim Test mit der absichtlich veränderten Domain kann der Hostname nicht aufgelöst werden. Die HTTP-Request-Node meldet deshalb einen Fehler.
Der entscheidende Pain Point: Der Flow liefert keine normale Antwort mehr – aber wie erkennen und behandeln wir diesen Fehler gezielt?
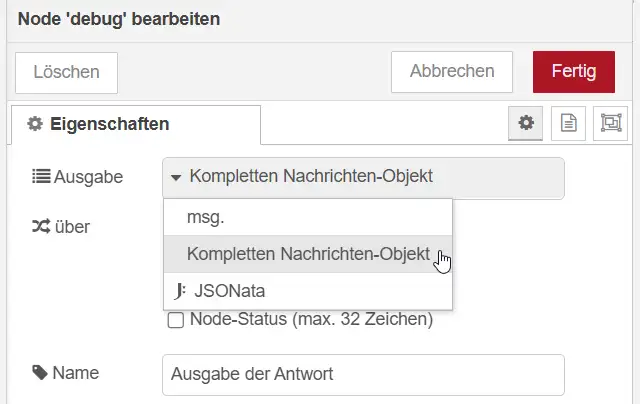
Ein erster wichtiger Hinweis kann bereits über die Debug-Node am Ende des Flows sichtbar werden. Dafür sollte sie jedoch nicht nur msg.payload, sondern das vollständige Nachrichtenobjekt ausgeben.
Fehlerinformationen befinden sich häufig in zusätzlichen Eigenschaften der Nachricht und wären bei einer reinen Ausgabe von msg.payload nicht zu sehen. Durch die Einstellung „vollständiges Nachrichtenobjekt“ lassen sich deshalb neben dem Payload auch weitere Informationen untersuchen, die bei der Eingrenzung eines Fehlers helfen können.
Allerdings erhält eine direkt angeschlossene Debug-Node im Fehlerfall nicht immer eine Nachricht. Meldet die betreffende Node den Fehler ausschließlich an die Node-RED-Laufzeit, muss dieser über eine Catch-Node abgefangen werden.
Das ist ein guter erster Schritt bei der Fehlersuche. Betrachtet man allerdings nur den sogenannten Happy Case und geht fest davon aus, dass die Adresse immer erreichbar ist, würde der Flow an dieser Stelle im Fehlerfall schlicht nicht wie erwartet weiterlaufen.
Genau hier beginnt das eigentliche Problem: Der Flow kann an einer Stelle stoppen, an der wir eigentlich mit einer Antwort gerechnet haben. Deshalb reicht eine Debug-Node allein oft nicht aus. Für eine saubere Fehlerbehandlung in Node-RED schauen wir uns im nächsten Schritt an, wie sich Fehler gezielt mit einer Catch-Node abfangen lassen.
Fehler mit der Catch-Node gezielt abfangen
Die Debug-Node hilft uns dabei, Nachrichten und mögliche Fehler genauer zu untersuchen. Sie reagiert jedoch nur auf Nachrichten, die sie über eine direkte Verbindung erhält. Für eine gezielte Fehlerbehandlung stellt Node-RED deshalb die Catch-Node bereit.
Wichtig: Die Catch-Node kann nur Fehler verarbeiten, die von einer Node als abfangbarer Fehler an die Node-RED-Laufzeit gemeldet werden. Manche Nodes schreiben Fehler lediglich in das Protokoll oder ändern ihren sichtbaren Status. In solchen Fällen wird die Catch-Node nicht ausgelöst. Eine Statusänderung lässt sich gegebenenfalls stattdessen mit der Status-Node überwachen.
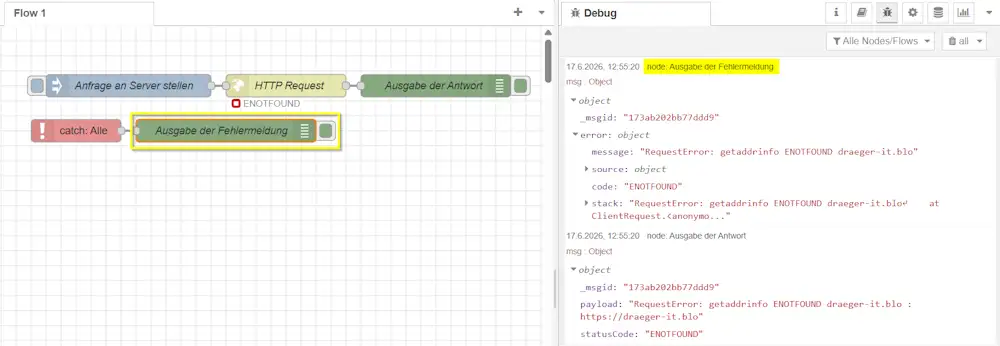
Die Catch-Node wird nicht direkt in den normalen Nachrichtenfluss eingebaut. Stattdessen überwacht sie andere Nodes innerhalb desselben Flows und wird ausgelöst, sobald eine überwachte Node einen abfangbaren Fehler meldet.
Für unser Beispiel erweitern wir den Flow zunächst um eine Catch-Node und eine weitere Debug-Node:
Node-RED Flow als JSON zum Importieren
[
{
"id": "34e4fe199e96c12e",
"type": "tab",
"label": "Flow 1",
"disabled": false,
"info": "",
"env": []
},
{
"id": "1fed1fa1c2946366",
"type": "inject",
"z": "34e4fe199e96c12e",
"name": "Anfrage an Server stellen",
"props": [
{
"p": "url",
"v": "https://draeger-it.blo",
"vt": "str"
}
],
"repeat": "",
"crontab": "",
"once": false,
"onceDelay": 0.1,
"topic": "",
"x": 190,
"y": 80,
"wires": [
[
"02edada60c105002"
]
]
},
{
"id": "02edada60c105002",
"type": "http request",
"z": "34e4fe199e96c12e",
"name": "HTTP Request",
"method": "GET",
"ret": "txt",
"paytoqs": "ignore",
"url": "",
"tls": "",
"persist": false,
"proxy": "",
"insecureHTTPParser": false,
"authType": "",
"senderr": false,
"headers": [],
"x": 400,
"y": 80,
"wires": [
[
"1c0dd8bbac0c8573"
]
]
},
{
"id": "1c0dd8bbac0c8573",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Ausgabe der Antwort",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 600,
"y": 80,
"wires": []
},
{
"id": "06272495c7e74077",
"type": "catch",
"z": "34e4fe199e96c12e",
"name": "",
"scope": null,
"uncaught": false,
"x": 120,
"y": 140,
"wires": [
[
"7e40a2e0d5e75996"
]
]
},
{
"id": "7e40a2e0d5e75996",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Ausgabe der Fehlermeldung",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 340,
"y": 140,
"wires": []
}
]
Inject → URL setzen → HTTP Request → Debug Catch → Debug
Die Catch-Node ist in diesem ersten Beispiel so eingestellt, dass sie alle abfangbaren Fehler innerhalb des aktuellen Flows überwacht. Schlägt der Aufruf der Webseite beispielsweise wegen einer unterbrochenen Internetverbindung oder einer ungültigen Adresse fehl, erzeugt die Catch-Node eine neue Nachricht für unseren Fehlerpfad.
Diese Nachricht enthält unter anderem die Eigenschaft msg.error. Darin finden wir Informationen zur Fehlermeldung und zu der Node, die den Fehler ausgelöst hat.
Typischerweise kann die Nachricht beispielsweise folgende Struktur enthalten:
{
"_msgid": "173ab202bb77ddd9",
"error": {
"message": "RequestError: getaddrinfo ENOTFOUND draeger-it.blo",
"source": {
"id": "02edada60c105002",
"type": "http request",
"name": "HTTP Request",
"count": 1
},
"code": "ENOTFOUND",
"stack": "RequestError: getaddrinfo ENOTFOUND draeger-it.blo\n at ClientRequest.<anonymous> (file:///usr/src/node-red/node_modules/got/dist/source/core/index.js:790:107)\n at Object.onceWrapper (node:events:639:26)\n at ClientRequest.emit (node:events:536:35)\n at emitErrorEvent (node:_http_client:101:11)\n at TLSSocket.socketErrorListener (node:_http_client:504:5)\n at TLSSocket.emit (node:events:524:28)\n at emitErrorNT (node:internal/streams/destroy:169:8)\n at emitErrorCloseNT (node:internal/streams/destroy:128:3)\n at process.processTicksAndRejections (node:internal/process/task_queues:82:21)\n at GetAddrInfoReqWrap.onlookupall [as oncomplete] (node:dns:122:26)"
}
}
Die genaue Fehlermeldung kann je nach Ursache unterschiedlich aussehen. Bei einer instabilen Netzwerkverbindung können beispielsweise Zeitüberschreitungen, DNS-Fehler oder Verbindungsabbrüche auftreten.
Da sich eine instabile Internetverbindung nicht zuverlässig reproduzieren lässt, erzeuge ich den Fehler für das folgende Beispiel bewusst. Dazu entferne ich das „g“ am Ende der Domain. Die URL verweist dadurch auf den nicht vorhandenen Hostnamen
draeger-it.blo.
Der große Vorteil: Über den Ausgang der Catch-Node können wir den Fehler nun kontrolliert weiterverarbeiten. Wir könnten ihn beispielsweise:
- im Debug-Fenster ausgeben,
- in einer Datei protokollieren,
- per MQTT versenden,
- als Benachrichtigung weiterleiten,
- oder nach einer kurzen Wartezeit einen erneuten Versuch starten.
Damit endet der Fehler nicht mehr unbemerkt innerhalb des ursprünglichen Flows. Stattdessen entsteht ein eigener Fehlerpfad, über den wir gezielt auf die jeweilige Situation reagieren können.
Fehler mit einer Switch-Node unterscheiden
Nachdem die Catch-Node den Fehler abgefangen hat, können wir die Nachricht mit einer Switch-Node genauer untersuchen. Dadurch lässt sich abhängig von der Fehlerursache unterschiedlich reagieren.
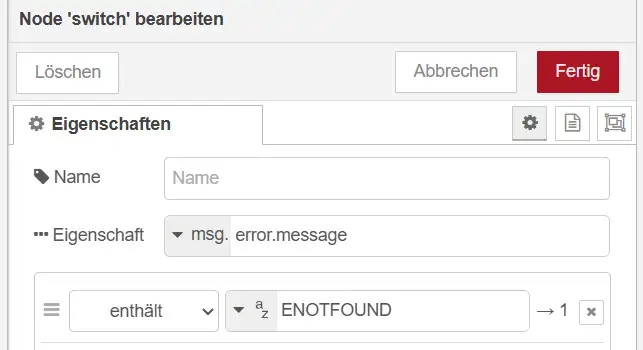
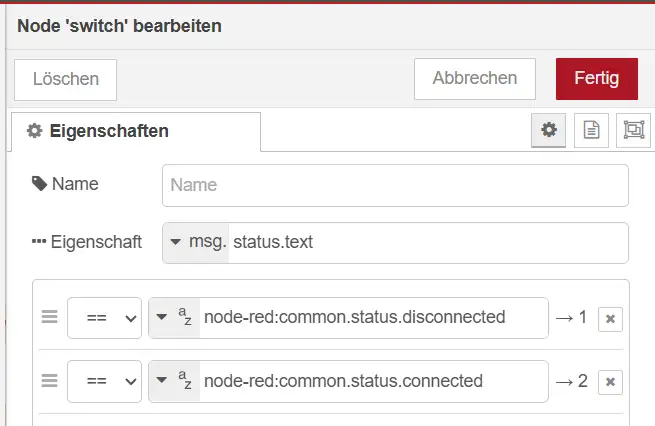
Die Fehlermeldung befindet sich in unserem Beispiel unter: msg.error.message
Bei einer nicht auflösbaren Adresse lautet die Meldung beispielsweise: RequestError: getaddrinfo ENOTFOUND draeger-it.blo
Der Bestandteil ENOTFOUND bedeutet, dass der angegebene Hostname nicht über das Domain Name System aufgelöst werden konnte. In diesem Beispiel wurde die Adresse absichtlich falsch geschrieben.
In der Switch-Node wählen wir deshalb folgende Eigenschaft aus: msg.error.message
Als Regel verwenden wir: enthält ENOTFOUND
Alternativ können wir in diesem Beispiel direkt die Eigenschaft msg.error.code auswerten. Diese enthält den Wert ENOTFOUND und ist damit eindeutiger als die vollständige Fehlermeldung unter msg.error.message.
Sofern msg.error.code vorhanden ist, sollte bevorzugt diese Eigenschaft ausgewertet werden. Falls eine Node keinen separaten Fehlercode liefert, kann alternativ nach einem eindeutigen Bestandteil wie ENOTFOUND innerhalb von msg.error.message gesucht werden.
Die Switch-Node leitet die Nachricht anschließend über einen eigenen Ausgang weiter. An diesem Ausgang könnten wir beispielsweise eine verständliche Meldung erzeugen, den Fehler protokollieren oder einen erneuten Aufruf vorbereiten.
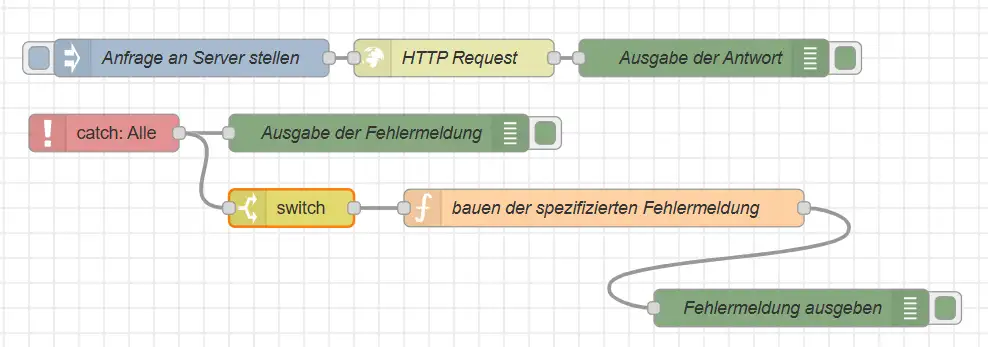
Node-RED Flow als JSON zum Importieren
[
{
"id": "34e4fe199e96c12e",
"type": "tab",
"label": "Flow 1",
"disabled": false,
"info": "",
"env": []
},
{
"id": "1fed1fa1c2946366",
"type": "inject",
"z": "34e4fe199e96c12e",
"name": "Anfrage an Server stellen",
"props": [
{
"p": "url",
"v": "https://draeger-it.blo",
"vt": "str"
}
],
"repeat": "",
"crontab": "",
"once": false,
"onceDelay": 0.1,
"topic": "",
"x": 190,
"y": 80,
"wires": [
[
"02edada60c105002"
]
]
},
{
"id": "02edada60c105002",
"type": "http request",
"z": "34e4fe199e96c12e",
"name": "HTTP Request",
"method": "GET",
"ret": "txt",
"paytoqs": "ignore",
"url": "",
"tls": "",
"persist": false,
"proxy": "",
"insecureHTTPParser": false,
"authType": "",
"senderr": false,
"headers": [],
"x": 400,
"y": 80,
"wires": [
[
"1c0dd8bbac0c8573"
]
]
},
{
"id": "1c0dd8bbac0c8573",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Ausgabe der Antwort",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 600,
"y": 80,
"wires": []
},
{
"id": "06272495c7e74077",
"type": "catch",
"z": "34e4fe199e96c12e",
"name": "",
"scope": null,
"uncaught": false,
"x": 120,
"y": 140,
"wires": [
[
"7e40a2e0d5e75996",
"b1bc78c235752bfd"
]
]
},
{
"id": "7e40a2e0d5e75996",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Ausgabe der Fehlermeldung",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 340,
"y": 140,
"wires": []
},
{
"id": "b1bc78c235752bfd",
"type": "switch",
"z": "34e4fe199e96c12e",
"name": "",
"property": "error.message",
"propertyType": "msg",
"rules": [
{
"t": "cont",
"v": "ENOTFOUND",
"vt": "str"
}
],
"checkall": "true",
"repair": false,
"outputs": 1,
"x": 270,
"y": 200,
"wires": [
[
"b8dcbfd71f5a3a7f"
]
]
},
{
"id": "8ecf3eecd3dc4b50",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Fehlermeldung ausgeben",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 670,
"y": 280,
"wires": []
},
{
"id": "b8dcbfd71f5a3a7f",
"type": "function",
"z": "34e4fe199e96c12e",
"name": "bauen der spezifizierten Fehlermeldung",
"func": "msg.payload = \"Die Adresse \" + msg.url + \" konnte nicht gefunden werden!\";\nreturn msg;",
"outputs": 1,
"timeout": 0,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [],
"x": 520,
"y": 200,
"wires": [
[
"8ecf3eecd3dc4b50"
]
]
}
]
Es ist sinnvoller, nur auf den Bestandteil ENOTFOUND zu prüfen und nicht die vollständige Fehlermeldung zu vergleichen. Der Domainname oder zusätzliche Bestandteile der Meldung können sich ändern, während der eigentliche Fehlercode gleich bleibt.
Catch-Node auf die HTTP-Request-Node begrenzen
In der bisherigen Konfiguration reagiert die Catch-Node auf Fehler aller Nodes innerhalb des aktuellen Flows. Für kleine Beispiele ist das zunächst praktisch. Sobald ein Flow jedoch größer wird und mehrere Nodes Fehler erzeugen können, lässt sich die Ursache schwieriger zuordnen.
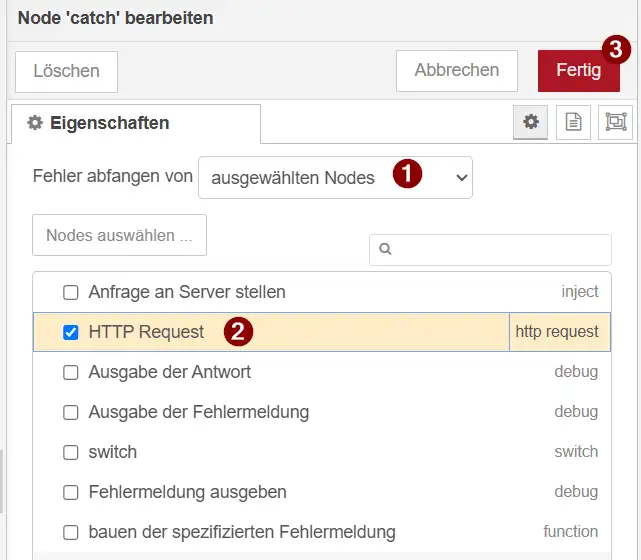
Deshalb können wir festlegen, welche Node von der Catch-Node überwacht werden soll.
Dazu öffnen wir die Catch-Node und wählen unter den überwachten Nodes ausschließlich die HTTP-Request-Node aus. Anschließend reagiert die Catch-Node nur noch auf Fehler, die von dieser Node gemeldet werden.
Das hat mehrere Vorteile:
- Fehler lassen sich eindeutig einer bestimmten Node zuordnen.
- Unterschiedliche Bereiche eines Flows können eigene Fehlerbehandlungen erhalten.
- Die Fehlerlogik bleibt auch bei größeren Flows übersichtlich.
- Unabhängige Fehler werden nicht versehentlich über denselben Fehlerpfad verarbeitet.
In unserem Beispiel ist die Begrenzung besonders sinnvoll, da wir ausschließlich auf Fehler beim Aufruf der Webseite reagieren möchten.
Der vereinfachte Aufbau sieht damit so aus:
HTTP Request → bei Erfolg → Debug HTTP-Fehler → Catch-Node → Switch-Node → spezifische Fehlerbehandlung
Node-RED Flow als JSON zum Importieren
[
{
"id": "34e4fe199e96c12e",
"type": "tab",
"label": "Flow 1",
"disabled": false,
"info": "",
"env": []
},
{
"id": "1fed1fa1c2946366",
"type": "inject",
"z": "34e4fe199e96c12e",
"name": "Anfrage an Server stellen",
"props": [
{
"p": "url",
"v": "https://draeger-it.blo",
"vt": "str"
}
],
"repeat": "",
"crontab": "",
"once": false,
"onceDelay": 0.1,
"topic": "",
"x": 190,
"y": 80,
"wires": [
[
"02edada60c105002"
]
]
},
{
"id": "02edada60c105002",
"type": "http request",
"z": "34e4fe199e96c12e",
"name": "HTTP Request",
"method": "GET",
"ret": "txt",
"paytoqs": "ignore",
"url": "",
"tls": "",
"persist": false,
"proxy": "",
"insecureHTTPParser": false,
"authType": "",
"senderr": false,
"headers": [],
"x": 400,
"y": 80,
"wires": [
[
"1c0dd8bbac0c8573"
]
]
},
{
"id": "1c0dd8bbac0c8573",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Ausgabe der Antwort",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 600,
"y": 80,
"wires": []
},
{
"id": "06272495c7e74077",
"type": "catch",
"z": "34e4fe199e96c12e",
"name": "",
"scope": [
"02edada60c105002"
],
"uncaught": false,
"x": 110,
"y": 140,
"wires": [
[
"7e40a2e0d5e75996",
"b1bc78c235752bfd"
]
]
},
{
"id": "7e40a2e0d5e75996",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Ausgabe der Fehlermeldung",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 340,
"y": 140,
"wires": []
},
{
"id": "b1bc78c235752bfd",
"type": "switch",
"z": "34e4fe199e96c12e",
"name": "",
"property": "error.message",
"propertyType": "msg",
"rules": [
{
"t": "cont",
"v": "ENOTFOUND",
"vt": "str"
}
],
"checkall": "true",
"repair": false,
"outputs": 1,
"x": 270,
"y": 200,
"wires": [
[
"b8dcbfd71f5a3a7f"
]
]
},
{
"id": "8ecf3eecd3dc4b50",
"type": "debug",
"z": "34e4fe199e96c12e",
"name": "Fehlermeldung ausgeben",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 670,
"y": 280,
"wires": []
},
{
"id": "b8dcbfd71f5a3a7f",
"type": "function",
"z": "34e4fe199e96c12e",
"name": "bauen der spezifizierten Fehlermeldung",
"func": "msg.payload = \"Die Adresse \" + msg.url + \" konnte nicht gefunden werden!\";\nreturn msg;",
"outputs": 1,
"timeout": 0,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [],
"x": 520,
"y": 200,
"wires": [
[
"8ecf3eecd3dc4b50"
]
]
}
]
Die Catch-Node muss dabei nicht direkt mit der HTTP-Request-Node verbunden sein. Sie überwacht die ausgewählte Node unabhängig vom normalen Nachrichtenfluss.
Für größere Anwendungen können auch mehrere Catch-Nodes eingesetzt werden. So könnte beispielsweise eine Catch-Node Netzwerkfehler überwachen, während eine weitere Catch-Node für Fehler beim Speichern von Dateien oder beim Zugriff auf eine Datenbank zuständig ist.
Zustandsänderungen mit der Status-Node überwachen
Mit der Catch-Node können wir Fehler abfangen, die eine andere Node ausdrücklich an die Node-RED-Laufzeit meldet. Damit lassen sich beispielsweise Netzwerkfehler einer HTTP-Request-Node gezielt verarbeiten.
Nicht jede problematische Situation erzeugt jedoch automatisch einen solchen Fehler. Manche Nodes zeigen stattdessen unterhalb der Node einen aktuellen Zustand an. Typische Beispiele sind:
- verbunden
- getrennt
- Verbindung wird hergestellt
- deaktiviert
- Fehler
Solche Statusmeldungen sind besonders bei Nodes hilfreich, die dauerhaft mit einem externen Dienst oder Gerät verbunden bleiben. Dazu gehören beispielsweise MQTT-, Datenbank- oder Geräte-Nodes.
Mit der Status-Node können wir diese Zustandsänderungen erfassen und als normale Nachricht in einem Flow weiterverarbeiten. Dadurch lässt sich beispielsweise erkennen, wenn die Verbindung zu einem MQTT-Broker unterbrochen wurde.
Wichtig ist dabei: Die Status-Node ersetzt die Catch-Node nicht. Beide Nodes haben unterschiedliche Aufgaben:
| Node | Aufgabe |
|---|---|
| Catch-Node | reagiert auf gemeldete Fehler |
| Status-Node | reagiert auf Statusänderungen einer Node |
| Debug-Node | macht Nachrichten und deren Inhalt sichtbar |
Für das folgende Beispiel verwenden wir eine MQTT-Node, da sie ihren Verbindungsstatus direkt unterhalb der Node anzeigt. Wird der MQTT-Broker beendet oder ist nicht erreichbar, ändert sich dieser Status. Die Status-Node erkennt diese Änderung und gibt eine neue Nachricht aus.
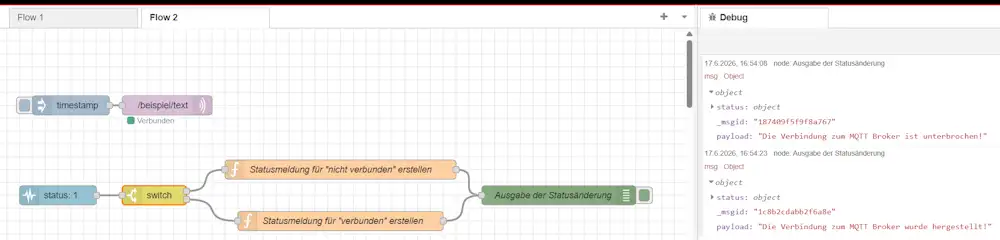
MQTT-Verbindung mit der Status-Node überwachen
In diesem Beispiel überwacht die Status-Node den Verbindungszustand einer MQTT-Out-Node. Als MQTT-Broker kommt Mosquitto zum Einsatz. Sobald der Broker gestoppt oder erneut gestartet wird, ändert sich der Status der MQTT-Node automatisch.
Node-RED Flow als JSON zum Importieren
[
{
"id": "8c105c2e4a45c10e",
"type": "tab",
"label": "Flow 2",
"disabled": false,
"info": "",
"env": []
},
{
"id": "7d1c53815cc56777",
"type": "inject",
"z": "8c105c2e4a45c10e",
"name": "",
"props": [
{
"p": "payload"
},
{
"p": "topic",
"vt": "str"
}
],
"repeat": "",
"crontab": "",
"once": false,
"onceDelay": 0.1,
"topic": "",
"payload": "",
"payloadType": "date",
"x": 120,
"y": 120,
"wires": [
[
"2e69599beb37b62d"
]
]
},
{
"id": "2e69599beb37b62d",
"type": "mqtt out",
"z": "8c105c2e4a45c10e",
"name": "",
"topic": "/beispiel/text",
"qos": "",
"retain": "",
"respTopic": "",
"contentType": "",
"userProps": "",
"correl": "",
"expiry": "",
"broker": "2dc0a4b70d96ebb5",
"x": 270,
"y": 120,
"wires": []
},
{
"id": "7113958f4b37c1cb",
"type": "status",
"z": "8c105c2e4a45c10e",
"name": "",
"scope": [
"2e69599beb37b62d"
],
"x": 100,
"y": 260,
"wires": [
[
"895156e15c61ffb6"
]
]
},
{
"id": "5edda4976ee422cb",
"type": "debug",
"z": "8c105c2e4a45c10e",
"name": "Ausgabe der Statusänderung",
"active": true,
"tosidebar": true,
"console": false,
"tostatus": false,
"complete": "true",
"targetType": "full",
"statusVal": "",
"statusType": "auto",
"x": 880,
"y": 260,
"wires": []
},
{
"id": "99ee96e58880f9fd",
"type": "function",
"z": "8c105c2e4a45c10e",
"name": "Statusmeldung für \"nicht verbunden\" erstellen",
"func": "msg.payload = \"Die Verbindung zum MQTT Broker ist unterbrochen!\";\nreturn msg;",
"outputs": 1,
"timeout": 0,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [],
"x": 540,
"y": 220,
"wires": [
[
"5edda4976ee422cb"
]
]
},
{
"id": "895156e15c61ffb6",
"type": "switch",
"z": "8c105c2e4a45c10e",
"name": "",
"property": "status.text",
"propertyType": "msg",
"rules": [
{
"t": "eq",
"v": "node-red:common.status.disconnected",
"vt": "str"
},
{
"t": "eq",
"v": "node-red:common.status.connected",
"vt": "str"
}
],
"checkall": "false",
"repair": false,
"outputs": 2,
"x": 250,
"y": 260,
"wires": [
[
"99ee96e58880f9fd"
],
[
"03e0329660e4c26b"
]
]
},
{
"id": "03e0329660e4c26b",
"type": "function",
"z": "8c105c2e4a45c10e",
"name": "Statusmeldung für \"verbunden\" erstellen",
"func": "msg.payload = \"Die Verbindung zum MQTT Broker wurde hergestellt!\";\nreturn msg;",
"outputs": 1,
"timeout": 0,
"noerr": 0,
"initialize": "",
"finalize": "",
"libs": [],
"x": 540,
"y": 300,
"wires": [
[
"5edda4976ee422cb"
]
]
},
{
"id": "2dc0a4b70d96ebb5",
"type": "mqtt-broker",
"name": "",
"broker": "mosquitto",
"port": 1883,
"clientid": "",
"autoConnect": true,
"usetls": false,
"protocolVersion": 4,
"keepalive": 60,
"cleansession": true,
"autoUnsubscribe": true,
"birthTopic": "",
"birthQos": "0",
"birthRetain": "false",
"birthPayload": "",
"birthMsg": {},
"closeTopic": "",
"closeQos": "0",
"closeRetain": "false",
"closePayload": "",
"closeMsg": {},
"willTopic": "",
"willQos": "0",
"willRetain": "false",
"willPayload": "",
"willMsg": {},
"userProps": "",
"sessionExpiry": ""
}
]
Die Status-Node erzeugt eine neue Nachricht mit dem Objekt msg.status. Darin befinden sich unter anderem der Statustext, die Farbe und die Form des angezeigten Statussymbols sowie Informationen zur Node, die die Änderung ausgelöst hat. Für unsere Auswertung ist insbesondere msg.status.text relevant.

Im Video stoppe ich zunächst den Mosquitto-Broker. Daraufhin wechselt die MQTT-Out-Node in den Zustand „nicht verbunden“. Die Status-Node erfasst diese Änderung und leitet sie an die Switch-Node weiter.
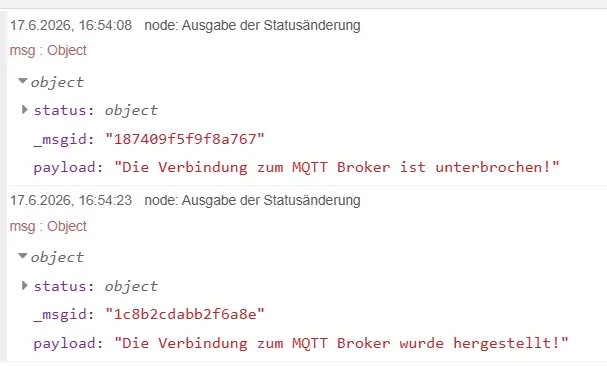
Anschließend wird im Debug-Bereich folgende Meldung ausgegeben:
Die Verbindung zum MQTT Broker ist unterbrochen!
Nachdem der Mosquitto-Broker wieder gestartet wurde, stellt Node-RED die MQTT-Verbindung automatisch erneut her. Auch diese Statusänderung wird erkannt und im Debug-Bereich ausgegeben:
Die Verbindung zum MQTT Broker wurde hergestellt!
Damit lässt sich sehr einfach überprüfen, ob ein MQTT-Broker verfügbar ist. Anstelle einer einfachen Debug-Ausgabe könnte später beispielsweise eine Warnmeldung, eine E-Mail oder eine Push-Benachrichtigung ausgelöst werden.
Statusmeldung mit einer Switch-Node auswerten
Die Status-Node übergibt die Informationen zur überwachten Node innerhalb des Nachrichtenobjekts. Der eigentliche Statustext befindet sich unter:
msg.status.text
Die Switch-Node prüft in diesem Beispiel auf zwei mögliche Werte:
node-red:common.status.disconnected
und:
node-red:common.status.connected
Beim Status disconnected wird der erste Ausgang verwendet. Die daran angeschlossene Function-Node erzeugt die Meldung:
msg.payload = "Die Verbindung zum MQTT Broker ist unterbrochen!"; return msg;
Wird die Verbindung wiederhergestellt, verwendet die Switch-Node den zweiten Ausgang. Die zweite Function-Node setzt daraufhin folgende Nachricht:
msg.payload = "Die Verbindung zum MQTT Broker wurde hergestellt!"; return msg;
Beide Meldungen werden anschließend an dieselbe Debug-Node übergeben und im Debug-Bereich von Node-RED angezeigt.
Warum wird die Status-Node auf eine Node begrenzt?
In der Konfiguration der Status-Node wurde ausschließlich die MQTT-Out-Node ausgewählt. Dadurch reagiert die Status-Node nur auf Änderungen dieser einen Node.
Ohne diese Einschränkung könnten auch Statusmeldungen anderer Nodes im Flow verarbeitet werden. Das würde die Auswertung unnötig kompliziert machen und könnte dazu führen, dass die Switch-Node nicht erwartete Statusmeldungen erhält.
Die gezielte Auswahl der zu überwachenden Node sorgt daher für einen übersichtlichen und kontrollierten Ablauf.
Fazit: Welche Node brauche ich für welchen Fehlerfall?
Die Debug-, Catch- und Status-Node erfüllen unterschiedliche Aufgaben und ergänzen sich bei der Fehlersuche in Node-RED.
Die Debug-Node hilft dabei, Nachrichten und deren Eigenschaften sichtbar zu machen. Die Catch-Node reagiert auf Fehler, die von einer Node an die Node-RED-Laufzeit gemeldet werden. Die Status-Node überwacht dagegen Zustandsänderungen, beispielsweise die Verbindung zu einem MQTT-Broker.
Für eine robuste Anwendung reicht es deshalb häufig nicht aus, nur eine dieser Nodes einzusetzen. Eine Kombination aus Debug-, Catch- und Status-Node sorgt dafür, dass Fehler sichtbar werden, kontrolliert verarbeitet werden und Verbindungsabbrüche nicht unbemerkt bleiben.
Im nächsten Schritt könnten die erkannten Fehler beispielsweise protokolliert, per MQTT versendet oder als Push-Nachricht weitergeleitet werden.
Ausblick: Fehler in Node-RED dauerhaft protokollieren
In diesem Beitrag haben wir Fehler und Statusänderungen zunächst erkannt, ausgewertet und im Debug-Bereich sichtbar gemacht. Für eine langfristige Überwachung reicht eine reine Debug-Ausgabe jedoch meist nicht aus.
Gerade bei unbeaufsichtigten Flows ist es wichtig, später nachvollziehen zu können, wann ein Fehler aufgetreten ist, welche Node ihn ausgelöst hat und welche Meldung dabei erzeugt wurde. Dafür müssen die Informationen dauerhaft in einer Logdatei gespeichert werden.
Im nächsten Teil zeige ich dir deshalb zwei Möglichkeiten, Fehler in Node-RED zu protokollieren. Zunächst setzen wir das Logging mit den vorhandenen Bordmitteln von Node-RED um. Anschließend stelle ich eine eigene Logger-Node vor, die viele wiederkehrende Schritte übernimmt und das Speichern strukturierter Logeinträge deutlich komfortabler macht.
Letzte Aktualisierung am: 22. Juni 2026

1 thought on “Node-RED Fehler finden: Catch-, Status- und Debug-Node einfach erklärt”