Im ersten Teil Crawler für Webseite mit Python3 Programmieren – Teil 1 – Meta Daten auslesen haben wir die Meta-Daten aus einer Webseite gelesen und uns in der Konsole ausgeben lassen.
In diesem Beitrag möchte ich nun anknüpfend an den ersten Teil erläutern, wie wir diese Daten zunächst in einer CSV Datei und später in einer Microsoft Excel Mappe speichern.
Vorbereitung
Damit wir die Daten später komfortable in eine CSV Datei oder Excel Mappe speichern können, speichern wir uns diese zunächst in einem Objekt ab. Dieses hat den Vorteil das wir die Funktion des ladens / lesens der Daten später auswechseln können ohne das speichern anfassen zu müssen. Es muss jedoch darauf geachtet werden das die Datenstruktur beibehalten wird.
Ich lese hier die Meta-Daten zu einem meiner Blogbeiträge ein und speichere mir die Meta-Daten
- Author,
- Titel und
- Beschreibung
in mein Objekt „Meta“ ab.
Zum Schluß gebe ich diese Werte auf der Konsole aus.
from bs4 import BeautifulSoup
import requests
class Meta():
def __init__(self):
self.author = '-undefined-'
self.title = '-undefined-'
self.description = '-undefined-'
def setAuthor(self, author):
self.author = author
def setDescription(self, description):
self.description = description
def setTitle(self, title):
self.title = title
req = requests.get("https://draeger-it.blog/arduino-lektion-92-kapazitiver-touch-sensor-test-mit-einer-aluminiumplatte/")
beautifulSoup = BeautifulSoup(req.content, "html.parser")
metaDaten = Meta()
for tag in beautifulSoup.select('meta'):
if tag.get("name", None) == "author":
metaDaten.setAuthor(tag.get("content", None))
if tag.get("name", None) == "description":
metaDaten.setDescription(tag.get("content", None))
if tag.get("property", None) == "og:title":
metaDaten.setTitle(tag.get("content", None))
print(metaDaten.__dict__)
Ausgabe auf der Konsole:
{'title': 'Arduino Lektion #92: kapazitiver Touch Sensor - Test mit einer Aluminiumplatte', 'author': 'Stefan Draeger', 'description': 'In diesem kleinen Beitrag zeige ich wie sich der kapazitive Touch Sensor unter einer Aluminiumplatte verhält.'}
Daten als CSV Datei speichern
Der wohl einfachste Weg ist die Daten als CSV Datei zu speichern. Eine CSV Datei ist eine „normale“ ASCII Datei in welcher die Daten durch einen definierbaren Separator getrennt sind. Meistens wird ein Semikolon „;“ als Trenner zwischen den einzelnen Daten gewählt.
Spalt1;Spalte2;Spalte3;Spalte4 Test;123;Stefan;Max
Vorteil
Eines der großen Vorteile des CSV Formates ist es das die Datei ohne zusätzliche Anwendungen in jedem Editor lesbar und beschreibbar ist.
Nachteil
Jeder Wert in einer Datenzeile wird durch einen Separator getrennt, sollte jedoch dieser Separator in dem Text vorkommen so wird ggf. die Struktur verändert.
Spalt1;Spalte2;Spalte3;Spalte4 Test;1;3;5;7;Stefan;Max
Hier muss man den Text in Anführungszeichen setzen damit der Separator nicht in die Struktur übernommen wird. Jedoch muss man wiederum darauf achten das auch kein Anführungszeichen in dem Text vorkommt. Es ist also ein recht einfaches Datenformat, aber mit einigen Risiken.
In der nachfolgenden Funktion öffnen wir die Datei „metaDaten.csv“ und schreiben dort die Meta-Daten hinein.
def speichernAlsCSV(metaDaten):
with open("metaDaten.csv", "a") as file:
file.write(metaDaten.author)
file.write(';')
file.write(metaDaten.title)
file.write(';')
file.write(metaDaten.description)
file.write(';')
file.write('\n')
Am Ende darf jedoch nicht vergessen werden ein Zeilenumbruch hinzuzufügen.
Durch den Parameter „a“ beim öffnen der Datei wird der Modus „append“ aktiviert, d.h. bei jedem ausführen des Skriptes wird eine zusätzliche Zeile geschrieben.
Auswerten aller Seiten / Beiträge einer WordPress Webseite
Bisher haben wir nur eine Seite bzw. Beitrag geladen und verarbeitet, wollen wir jedoch alle Seite oder Beiträge einer Webseite verarbeiten so könnten wir zunächst auf der Startseite beginnen und jeden Hyperlink welcher auf der Seite verweist folgen. Dieses ist jedoch sehr fehleranfällig da es ggf. Seiten geben könnte welche keine internen Links haben.
Also wie bekommen wir nun eine Liste aller Seiten & Beiträge zu einer Webseite?
Unter WordPress gibt es das Plugin Yoast welches unter anderem das Feature anbietet eine solche sitemap.xml zu erstellen und automatisch bereit zu stellen.
Die Datei sitemap_index.xml wird unter den Link https://<<ADRESSE>>/sitemap_index.xml bereitgestellt. Und beinhaltet wiederum jeweils nach Kategorie sortierte Listen. Je nach Webseite kann diese Liste mal länger oder kürzer sein.
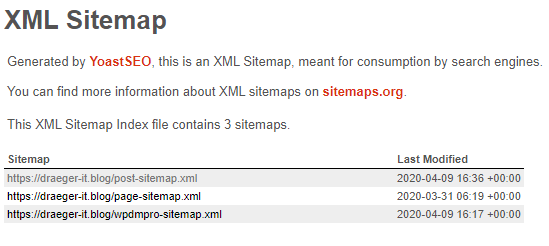
Uns interessiert zunächst nur die Datei https://<<ADRESSE>>/post-sitemap.xml, diese enthält alle Adressen der Beiträge der Webseite.
Zunächst benötigen wir eine Funktion zum laden und auswerten der Datei „post-sitemap.xml“, damit wir wiederum die Urls laden und auswerten können.
Wir starten mit der Funktion „loadPostsUrls“ und übergeben dort als Parameter-Wert die Adresse zur Datei „post-sitemap.xml“. Als Ergebnis dieser Funktion erhalten wir eine Liste mit Urls zu den Beiträgen welche wir danach in einer Schleife wie bereits gezeigt verarbeiten.
Da dieser Vorgang etwas dauert (je nach Rechen-/Internet Leistung) geben wir die Urls auf der Konsole aus und am Ende noch die Ausgabe „ENDE“.
def loadPostsUrls(startUrl):
req = requests.get(startUrl)
beautifulSoup = BeautifulSoup(req.content, "html.parser")
return [loc.text for loc in beautifulSoup.find_all('loc')]
posts = loadPostsUrls('https://draeger-it.blog/post-sitemap.xml')
for post in posts:
print(post)
req = requests.get(post)
beautifulSoup = BeautifulSoup(req.content, "html.parser")
metaDaten = Meta()
for tag in beautifulSoup.select('meta'):
if tag.get("name", None) == "author":
metaDaten.setAuthor(tag.get("content", None))
if tag.get("name", None) == "description":
metaDaten.setDescription(tag.get("content", None))
if tag.get("property", None) == "og:title":
metaDaten.setTitle(tag.get("content", None))
speichernAlsCSV(metaDaten)
print('ENDE')
SEO Richtlinien
Als nächstes wollen wir diese Seiten gem. den allgemeinen SEO Richtlinien bewerten.
Ich möchte folgende Richtlinien zur Bewertung festhalten:
- Titel
- 65 Zeichen lang
- Beschreibung
- vorhanden und
- 155 bis 160 Zeichen lang
Es gibt natürlich noch viele viele weitere Richtlinien jedoch sollen diese 3 Bedingungen erstmal ausreichen.
prüfen & speichern der Daten in einer Microsoft Excel Mappe
Wir haben bereits die Daten ausgelesen und in einer CSV Datei gespeichert. Nun möchten wir diese Daten nach den bereits genannten Richtlinien prüfen und zusätzlich ein einer Microsoft Excel Mappe speichern.
Das speichern der Daten in Excel hat den Vorteil das man zusätzlich die Zellen farblich hervorheben sowie aus den gewonnenen Daten ein Diagramm zeichnen kann.
Bibliothek XlsxWriter
Für das schreiben der Daten in eine Excel Mappe verwende ich die Bibliothek XlsxWriter welche du unter https://xlsxwriter.readthedocs.io/ zum Download findest. Auf der Seite findest du auch die sehr gute Dokumentation und sehr viele nützliche Beispiele.
Da ich auch hier wieder die IDE Anaconda mit der Erweiterung jupyter verwende, brauche ich mir dieses Paket nicht zusätzlich installieren.
Bevor wir eine Funktion dieser Bibliothek aufrufen können müssen wir diese natürlich erstmal importieren.
import xlsxwriter
ein kleines Beispiel
Bevor wir unsere Daten in die Excel Mappe speichern möchte ich kurz zeigen wie einfach es mit dieser Bibliothek ist Daten in eine Xlsx Datei zu schreiben.
#Bibliothek zum beschreiben von Excel Mappen
import xlsxwriter
#erstellen eines Workbook Elementes
#und zusätzlich die Datei im System anlegen
workbook = xlsxwriter.Workbook('einfaches_beispiel.xlsx')
#erstellen einer Seite im Excel Dokument
worksheet = workbook.add_worksheet('Beispiel')
#anlegen eines Zellenformates im Workbook
#dieses gilt für die gesamte Mappe
cF_bg_red = workbook.add_format()
#setzen der Hintergrundfarbe "rot"
cF_bg_red.set_bg_color('red')
#anlegen eines weiteren Zellenformates im Workbook
#jedoch mit mehr Attributen
cF_complex = workbook.add_format({
'align': 'center',
'valign': 'vcenter',
'bold': 1})
cF_complex.set_font_color('green')
#Beschreiben der Zellen
worksheet.write('A1', 'Dies')
worksheet.write('B1', 'ist',cF_bg_red)
worksheet.write('C1', 'ein')
worksheet.write('D1', 'Test',cF_complex)
#Schließen des Dokumentes
workbook.close()
Das Ergebnis ist, das wir eine Excel Mappe mit einer Datenzeile haben welche verschieden Formatiert ist.

speichern der Daten aus dem Meta Objekt
Das speichern der Daten erfolgt analog zum speichern der CSV Datei, d.h. wir analysieren eine Seite erhalten daraus ein Meta Objekt und dieses schreiben wir in die Excel Mappe.
Öffnen der Datei und erstellen des Workbooks sowie eines Reiters
Nachdem wir die Liste mit den Adressen geladen haben und diese nicht leer ist, erstellen wir unsere Xlsx Datei uns das erste Worksheet.
Als Name für die Tabelle kann jedes ASCII Zeichen außer \ , / , * , ? , : , [ , ]. verwendet werden!
posts = loadPostsUrls('https://draeger-it.blog/post-sitemap.xml')
if len(posts) > 0:
workbook = xlsxwriter.Workbook('crawler_1_.xlsx')
worksheet = workbook.add_worksheet()
Wenn man der Funktion „add_worksheet“ keinen Namen übergibt so wird der Standard von Excel verwendet.
Tabellenkopf
Nachdem die Datei erstellt wurde, erzeugen wir den Tabellenkopf.
worksheet.write('A1', '')
worksheet.write('B1', 'Titel')
worksheet.write('C1', 'Laenge')
worksheet.write('D1', 'MetaDescription')
worksheet.write('E1', 'Laenge')
worksheet.write('F1', 'Adresse')
Daten speichern
Zum speichern der Daten verwenden wir wieder eine zusätzliche Funktion welcher wir das Meta Objekt sowie dieses mal einen Index für die Zeile übergeben.
Da wir in der ersten Zeile unseren Tabellenkopf geschrieben haben, müssen wir zunächst zu unserem Index die Zahl 1 aufaddieren (sonst würde dieser ja überschrieben werden), zusätzlich müssen wir aus diese Zahl in einen String konvertieren damit wir diese zum Zeichen der Zelle (A,B C …) konkatinieren können.
def speichernAlsXlsx(metaDaten, index):
rowNum = str(index+1)
worksheet.write('A'+rowNum, str(index))
worksheet.write('B'+rowNum, metaDaten.title)
worksheet.write('C'+rowNum, str(len(metaDaten.title)))
worksheet.write('D'+rowNum, metaDaten.description)
worksheet.write('E'+rowNum, str(len(metaDaten.description)))
worksheet.write('F'+rowNum, metaDaten.adresse)
Das Ergebnis ist nun das die gelesenen Meta-Daten in der Excel Mappe geschrieben wurden.
Formatieren der Zellenwerte
Nun möchten wir noch, wie eingangs erwähnt die Zellen je nach Wert formatieren so das wir sehen welchen Titel bzw. welche Beschreibung optimiert werden sollte.
Wir können nun zwei Wege nutzen dieses zu tun.
Weg 1 – Bedingte Abfrage mit Zellenformatierung
Zunächst definieren wir die Farbe für den Hintergrund der Zellen. Ich wähle hier Pastellfarben da die „normalen“ Farbwerte (red, green und yellow) sehr grell sind.
cF_green = workbook.add_format()
cF_green.set_bg_color('#C0E2BD')
cF_red = workbook.add_format()
cF_red.set_bg_color('#F9D1D1')
cF_yellow = workbook.add_format()
cF_yellow.set_bg_color('#F9FCD0')
Als nächstes müssen wir dann nur in der Funktion, wo wir die Daten schreiben auf die SEO Richtlinien prüfen und je nachdem den Farbwert setzen.
def speichernAlsXlsx(metaDaten, index):
rowNum = str(index+1)
worksheet.write('A'+rowNum, str(index))
titleFormat = cF_green
if len(metaDaten.title) >= 0 and len(metaDaten.title) < 65:
titleFormat = cF_red
if len(metaDaten.title) == 65:
titleFormat = cF_green
if len(metaDaten.title) > 65:
titleFormat = cF_yellow
worksheet.write('B'+rowNum, metaDaten.title, titleFormat)
worksheet.write('C'+rowNum, str(len(metaDaten.title)), titleFormat)
descriptionFormat = cF_green
if len(metaDaten.description) >= 0 and len(metaDaten.description) < 155:
descriptionFormat = cF_red
if len(metaDaten.description) > 155 and len(metaDaten.description) < 165:
descriptionFormat = cF_green
if len(metaDaten.description) > 165:
descriptionFormat = cF_yellow
worksheet.write('D'+rowNum, metaDaten.description, descriptionFormat)
worksheet.write('E'+rowNum, str(len(metaDaten.description)),descriptionFormat)
worksheet.write('F'+rowNum, metaDaten.adresse)
Weg 2 – Bedingte Formatierung in Excel
In Excel gibt es die Funktion das man einer Zelle eine Funktion gibt welche automatisch je nach Zellenwert eine Formatierung setzt. Dieses nennt man „Bedingte Formatierung“.
import xlsxwriter
workbook = xlsxwriter.Workbook('bedingteFormatierung.xlsx')
worksheet = workbook.add_worksheet()
worksheet.write('A1', 'Zahl')
for i in range(9):
worksheet.write('A'+str(i+2), i)
format_green = workbook.add_format({'bg_color': '#C0E2BD', 'font_color': '#006100'})
format_yellow = workbook.add_format({'bg_color': '#F9FCD0', 'font_color': '#006100'})
format_red = workbook.add_format({'bg_color': '#F9D1D1', 'font_color': '#006100'})
worksheet.conditional_format('A2:A10', {'type': 'cell',
'criteria': '<',
'value': 5,
'format': format_green})
worksheet.conditional_format('A2:A10', {'type': 'cell',
'criteria': 'between',
'minimum': 5,
'maximum': 10,
'format': format_yellow})
worksheet.conditional_format('A2:A10', {'type': 'cell',
'criteria': '>=',
'value': 10,
'format': format_red})
workbook.close()
Als Beispiel zur Bedingten Formatierung erstelle ich hier eine Excel Mappe mit 10 Werten welche je nach Größe verschiedenfarbig dargestellt werden.
Wenn die Zahl kleiner als 5 ist, wird die Hintergrundfarbe der Zelle in „grün“ dargestellt.
Wenn die Zahl größer / gleich 5 ist, wird die Hintergrundfarbe der Zelle in „gelb“ dargestellt.
Wenn die Zahl größer / gleich 10 ist, wird die Hintergrundfarbe der Zelle in „rot“ dargestellt.
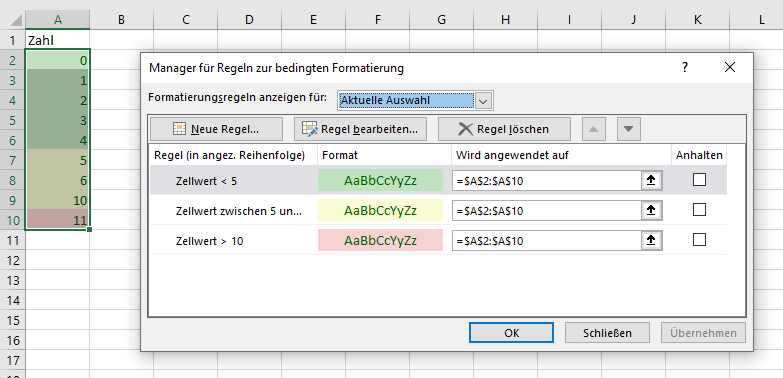
Für den Bericht möchte ich nun auf die Bedingte Formatierung zurückgreifen, diese ist deutlich komfortabler als die Lösung mit der Bedingten Abfrage und das setzen der Formatierung.
Skript für die Formatierung erweitern
Wollen wir nun die Werte in unserer Excel Mappe mithilfe der Bedingten Formatierung je nach Wert einfärben.
from bs4 import BeautifulSoup
import requests
import xlsxwriter
class Meta():
def __init__(self):
self.author = '-undefined-'
self.title = ''
self.description = ''
self.adresse = ''
def setAuthor(self, author):
self.author = author
def setDescription(self, description):
self.description = description
def setTitle(self, title):
self.title = title
def setAdresse(self, adresse):
self.adresse = adresse
def speichernAlsXlsx(metaDaten, index):
rowNum = str(index+1)
worksheet.write('A'+rowNum, str(index))
worksheet.write('B'+rowNum, metaDaten.title)
worksheet.write('C'+rowNum, len(metaDaten.title))
worksheet.write('D'+rowNum, metaDaten.description)
worksheet.write('E'+rowNum, len(metaDaten.description))
worksheet.write('F'+rowNum, metaDaten.adresse)
def loadPostsUrls(startUrl):
req = requests.get(startUrl)
beautifulSoup = BeautifulSoup(req.content, "html.parser")
return [loc.text for loc in beautifulSoup.find_all('loc')]
posts = loadPostsUrls('https://draeger-it.blog/post-sitemap.xml')
if len(posts) > 0:
workbook = xlsxwriter.Workbook('crawler_1_.xlsx')
worksheet = workbook.add_worksheet()
worksheet.write('A1', '')
worksheet.write('B1', 'Titel')
worksheet.write('C1', 'Laenge')
worksheet.write('D1', 'MetaDescription')
worksheet.write('E1', 'Laenge')
worksheet.write('F1', 'Adresse')
index = 0
for post in posts:
index = index + 1
print(post)
req = requests.get(post)
beautifulSoup = BeautifulSoup(req.content, "html.parser")
metaDaten = Meta()
metaDaten.setAdresse(post)
for tag in beautifulSoup.select('meta'):
if tag.get("name", None) == "author":
metaDaten.setAuthor(tag.get("content", None))
if tag.get("name", None) == "description":
metaDaten.setDescription(tag.get("content", None))
if tag.get("property", None) == "og:title":
metaDaten.setTitle(tag.get("content", None))
speichernAlsXlsx(metaDaten, index)
format_green = workbook.add_format({'bg_color': '#C0E2BD', 'font_color': '#006100'})
format_yellow = workbook.add_format({'bg_color': '#F9FCD0', 'font_color': '#006100'})
format_red = workbook.add_format({'bg_color': '#F9D1D1', 'font_color': '#006100'})
index = index + 1
worksheet.conditional_format('C2:C'+str(index), {'type': 'cell', 'criteria': '<', 'value': 60, 'format': format_yellow})
worksheet.conditional_format('C2:C'+str(index), {'type': 'cell', 'criteria': 'between', 'minimum': 60, 'maximum': 65, 'format': format_green})
worksheet.conditional_format('C2:C'+str(index), {'type': 'cell', 'criteria': '>=', 'value': 66, 'format': format_red})
worksheet.conditional_format('E2:E'+str(index), {'type': 'cell', 'criteria': '<', 'value': 154, 'format': format_yellow})
worksheet.conditional_format('E2:E'+str(index), {'type': 'cell', 'criteria': 'between', 'minimum': 155, 'maximum': 165, 'format': format_green})
worksheet.conditional_format('E2:E'+str(index), {'type': 'cell', 'criteria': '>=', 'value': 166, 'format': format_red})
workbook.close()
print('ENDE')
Ergebnis und Ausblick
Wir haben nun unsere Daten in ein Microsoft Excel Dokument geschrieben und je nach Zellenwert eingefärbt.
Im nächsten Teil wollen wir dann diese Daten in ein Liniendiagramm visualisieren und uns ein Überblick über die Werte verfassen.
Letzte Aktualisierung am: 01. Mai 2023
