Im vorherigen Beitrag haben wir uns angeschaut, wie der Node-RED Context funktioniert und wie du Werte ohne Datenbank zwischenspeichern kannst.
Dabei gab es aber einen wichtigen Hinweis:
In der Standardkonfiguration werden Context-Werte im Arbeitsspeicher gespeichert. Wird Node-RED neu gestartet, der Docker-Container beendet oder der Raspberry Pi neu gebootet, können diese Werte verloren gehen.
In diesem Beitrag zeige ich dir, wie du den Node-RED Context persistent speicherst. Dadurch bleiben Werte auch nach einem Neustart erhalten.

Was bedeutet Persistent Context?
Persistent bedeutet dauerhaft gespeichert.
Beim normalen Context werden Werte im Arbeitsspeicher gehalten. Das ist schnell und für viele kleine Automationen völlig ausreichend.
Beim Persistent Context werden die Werte zusätzlich im Dateisystem gespeichert.
Das bedeutet:
- Node-RED läuft → Wert ist verfügbar
- Node-RED wird beendet → Wert bleibt gespeichert
- Node-RED startet neu → Wert kann wieder ausgelesen werden
Das ist besonders praktisch für:
- Zählerstände
- letzte Schaltzustände
- gespeicherte Grenzwerte
- einfache Konfigurationen
- Betriebsmodi
- Merker innerhalb eines Flows
Wichtig ist aber: Auch Persistent Context ist keine vollwertige Datenbank. Für große Messwertverläufe, Diagramme oder historische Auswertungen ist SQLite, InfluxDB oder MySQL weiterhin die bessere Wahl.
Standardverhalten: Context liegt nur im Arbeitsspeicher
Standardmäßig speichert Node-RED Context-Werte im Arbeitsspeicher.
Ein einfacher Zähler funktioniert also nur, solange Node-RED läuft:
let zaehler = context.get("zaehler") || 0;
zaehler++;
context.set("zaehler", zaehler);
msg.payload = {
zaehler: zaehler
};
return msg;
Nach einem Neustart beginnt dieser Zähler wieder bei 0, wenn kein persistenter Context eingerichtet ist.
Das ist kein Fehler im Flow, sondern das normale Standardverhalten.
Persistent Context in settings.js aktivieren
Um Context-Werte dauerhaft zu speichern, muss die Datei settings.js angepasst werden.
Dort wird der Bereich contextStorage ergänzt oder aktiviert.
Die einfache Variante sieht so aus:
contextStorage: {
default: {
module: "localfilesystem"
}
}
Damit verwendet Node-RED den eingebauten localfilesystem Context Store.
Die Werte werden dann nicht nur im Arbeitsspeicher gehalten, sondern zusätzlich lokal im Dateisystem gespeichert.
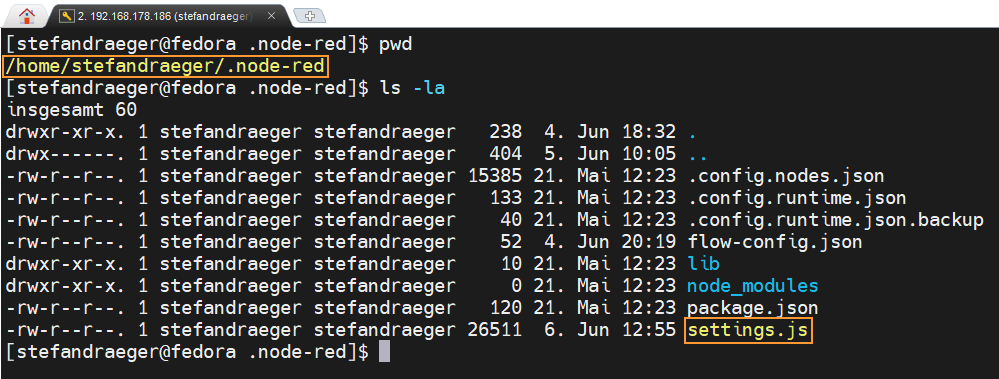
Wo liegt die settings.js?
Die Datei settings.js liegt normalerweise im Benutzerverzeichnis von Node-RED.
Typische Speicherorte sind:
/home/pi/.node-red/settings.js
/home/<benutzername>/.node-red/settings.js
Wichtig: Node-RED verwendet immer die settings.js aus dem Benutzerverzeichnis des Benutzers, unter dem Node-RED gestartet wurde.
Läuft Node-RED als normaler Benutzer, liegt die Datei meistens unter: /home/<Benutzername>/.node-red/settings.js
Läuft Node-RED dagegen als root, wird diese Datei verwendet: /root/.node-red/settings.js
Wenn Änderungen an der settings.js scheinbar keine Wirkung haben, wurde häufig die falsche Datei bearbeitet.
Bei einer Docker-Installation liegt die Datei meistens im eingebundenen /data-Verzeichnis des Containers.
Zum Beispiel:
/home/stefandraeger/.node-red/settings.js
Wichtig ist: Nach der Änderung muss Node-RED neu gestartet werden.
sudo systemctl restart nodered.service

Beispiel für Docker
Wenn Node-RED in Docker läuft, ist es besonders wichtig, dass das Datenverzeichnis dauerhaft eingebunden ist.
Ein typischer Ausschnitt aus einer docker-compose.yml sieht so aus:
services:
node-red:
image: nodered/node-red:latest
container_name: node-red
ports:
- "1880:1880"
volumes:
- ./node-red-data:/data
Der Ordner ./node-red-data liegt auf dem Host-System und wird in den Container unter /data eingebunden.
Dadurch bleiben die Node-RED-Daten auch erhalten, wenn der Container neu erstellt wird.
Wenn du Persistent Context verwendest, sollten auch die gespeicherten Context-Daten in diesem Bereich liegen.
Erweiterte Konfiguration
Der localfilesystem Store kann zusätzlich konfiguriert werden.
Ein Beispiel:
contextStorage: {
default: {
module: "localfilesystem",
config: {
cache: true,
flushInterval: 30
}
}
}
Mit cache: true werden Werte zusätzlich im Arbeitsspeicher gehalten.
Mit flushInterval: 30 legt Node-RED fest, in welchem Mindestabstand die Werte in das Dateisystem geschrieben werden.
Das bedeutet: Die Werte werden nicht zwangsläufig bei jeder einzelnen Änderung sofort auf die Festplatte geschrieben.
Für normale Automationen ist der Standardwert in der Regel vollkommen ausreichend.
Mehrere Context Stores verwenden
Du kannst auch mehrere Context Stores definieren.
Zum Beispiel:
contextStorage: {
default: "memoryOnly",
memoryOnly: {
module: "memory"
},
file: {
module: "localfilesystem"
}
}
Damit gibt es zwei Speicherbereiche:
memoryOnlyfür flüchtige Wertefilefür dauerhaft gespeicherte Werte
Einen Wert im normalen Speicher setzt du so:
flow.set("letzteTemperatur", 22.6);
Einen Wert gezielt im Dateispeicher setzt du so:
flow.set("letzteTemperatur", 22.6, "file");
Auslesen kannst du ihn entsprechend so:
let temperatur = flow.get("letzteTemperatur", "file");
Das ist praktisch, wenn du bewusst unterscheiden möchtest, welche Werte dauerhaft gespeichert werden und welche nur während der Laufzeit benötigt werden.
Test: Bleibt der Wert nach einem Neustart erhalten?
Nach der Einrichtung kannst du den persistenten Context einfach testen.
Dafür eignet sich ein kleiner Zähler.
Function Node:
let zaehler = flow.get("zaehler") || 0;
zaehler++;
flow.set("zaehler", zaehler);
msg.payload = {
zaehler: zaehler
};
return msg;
Starte den Flow mehrmals über eine Inject Node.
Danach sollte der Zähler hochzählen.
Jetzt startest du Node-RED neu.
Nach dem Neustart löst du den Flow erneut aus.
Wenn der Zähler nicht wieder bei 1 beginnt, sondern mit dem letzten Wert weitermacht, funktioniert der Persistent Context.
Wo werden die Context-Daten gespeichert?
Wenn der localfilesystem Store aktiviert ist, speichert Node-RED die Context-Daten als Dateien im Dateisystem.
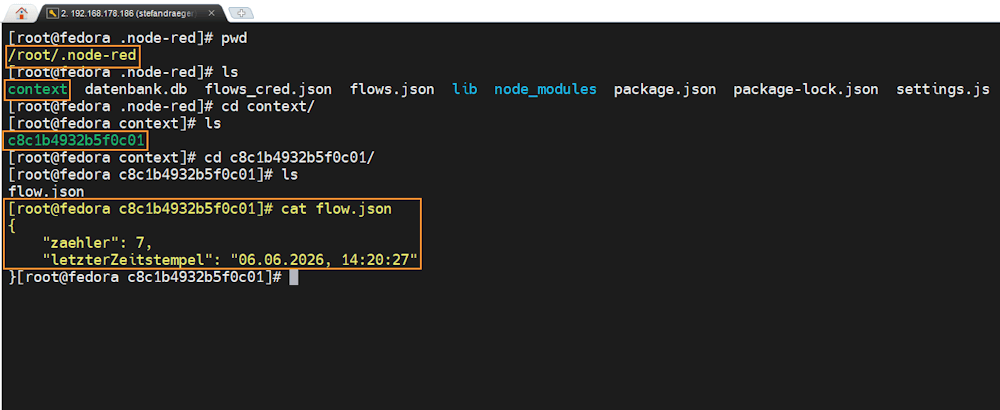
Standardmäßig findest du diese Dateien im Node-RED-Benutzerverzeichnis unter:
~/.node-red/context/
Bei einer normalen Installation kann der Pfad zum Beispiel so aussehen:
/home/pi/.node-red/context/
oder:
/home/<Benutzername>/.node-red/context/
In diesem Ordner legt Node-RED weitere Unterordner an. Für Flow-Context-Daten wird häufig ein Ordner mit einer internen ID verwendet. Darin befindet sich dann unter anderem eine Datei:
/home/<Benutzername>/.node-red/context/<ID>/flow.json
In dieser Datei werden die gespeicherten Werte des Flow Context als JSON abgelegt.
Ein gespeicherter Zähler kann dort zum Beispiel so aussehen:
{
"zaehler": 5,
"letzterZeitstempel": "06.06.2026, 10:15:30"
}
Wichtig: Die <ID> entspricht nicht unbedingt dem Namen deines Flow-Tabs, sondern einer internen ID, die Node-RED für den Flow verwendet.
Auch Global-Context-Daten werden in diesem Context-Verzeichnis gespeichert. Je nach Context-Art und Konfiguration legt Node-RED dafür eigene Dateien und Ordner an.
Wichtig bei Raspberry Pi und SD-Karte
Beim Raspberry Pi sollte man beachten, dass häufiges Schreiben auf die SD-Karte die Lebensdauer beeinflussen kann.
Deshalb sollte man nicht jede Sekunde große Datenmengen in den Persistent Context schreiben.
Für einzelne Zustände, Zähler oder Konfigurationen ist das unproblematisch.
Für viele Messwerte in kurzen Intervallen ist eine Datenbank oder eine speziellere Speicherlösung besser geeignet.
Wann sollte ich Persistent Context verwenden?
Persistent Context ist sinnvoll für:
- einfache Zähler
- letzte Zustände
- letzte bekannte Werte
- Konfigurationen
- Grenzwerte
- Betriebsmodi
- kleine Merker
Nicht ideal ist er für:
- große Messwert-Historien
- hochfrequente Sensorwerte
- Langzeitdiagramme
- viele tausend Datensätze
- komplexe Auswertungen
Als Faustregel gilt:
Persistent Context ist für wenige wichtige Zustände. Eine Datenbank ist für viele historische Werte.
Fazit
Mit dem Persistent Context kannst du Werte in Node-RED dauerhaft speichern, ohne direkt eine Datenbank zu verwenden.
Dafür wird in der Datei settings.js der localfilesystem Store aktiviert.
Das ist besonders praktisch, wenn einfache Zustände, Zähler oder Konfigurationen auch nach einem Neustart erhalten bleiben sollen.
Für große Datenmengen oder Messwertverläufe bleibt eine Datenbank aber weiterhin die bessere Lösung.
Letzte Aktualisierung am: 06. Juni 2026

1 thought on “Node-RED Context nach Neustart behalten – so geht’s”