In diesem Beitrag möchte ich dir zeigen wie du Bilder von einer Webseite automatisch auf deinen Computer herunterladen kannst.
Da Bilder, Text, Videos usw. meisten Urheberrechtlich geschützt sind gebe ich dir eine Subdomain zur Hand von welcher du die Daten frei verwenden kannst.
Wir werden im nachfolgenden die Bilder von http://ressourcen-draeger-it.de/progs/imgcrawler/index.html mit Python3 laden und verarbeiten. Dabei ist auf der Seite „nur“ eine Miniaturansicht des eigentlichen Bildes und wenn du auf das Bild klickst wird eine neue Seite geladen und dort dann das große Bild innerhalb der Seite angezeigt.
benötigte Bibliotheken
Damit wir die Webseite & die Bilder laden können, benutzen wir einige Bibliotheken welche ich dir nun zeigen werde.
requests
Die Bibliothek requests dient zum laden von Content von einer Adresse. Dabei kann der Inhalt (Content) beliebiger Herkunft sein!
urlib
Für die Verarbeitung der Url verwenden wir die Bibliothek urllib. Diese gibt diverse Funktionen / Module mit welchen wir zbsp. das Bild aus dem Internet laden können.
BeautifulSoup
Mit BeautifulSoup durchlaufen wir den HTML Baum und extraieren die benötigten Daten aus diesem.
os
Damit wir das Zielverzeichnis erstellen können benötigen wir die Bibliothek os.
Des Weiteren gibt uns diese Bibliothek zusätzlich die Funktion zum prüfen ob eine Datei / ein Verzeichnis existiert.
Aufbau der Webseite
Zunächst schauen wir uns die Webseite welche wir Crawlen / verarbeiten möchten an.
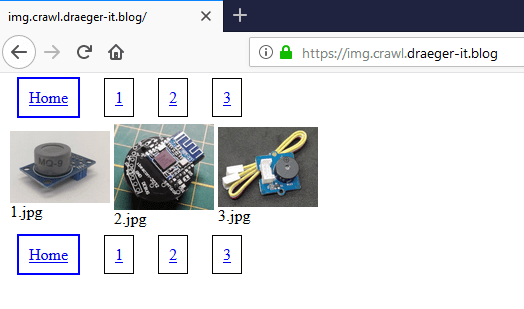
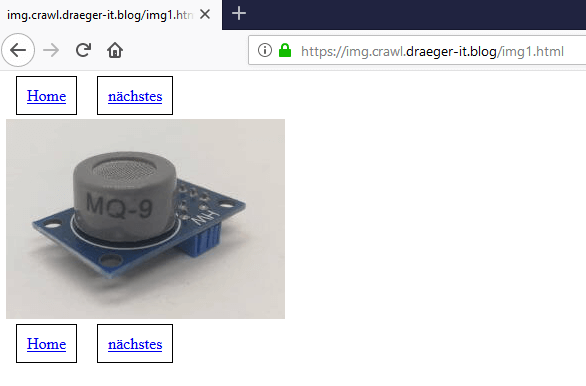


Auf der Startseite haben wir die Vorschaubilder in der Mitte. Oben und unten haben wir jeweils eine Seitenavigation. Wenn man auf ein Bild klickt so gelangt man zu einer Unterseite und findet dort das große Bild und auch hier zusätzlich eine Navigation um zum nächsten bzw. vorherigen Bild zu springen. Jedoch ist bei dem ersten und letzten Bild der Hyperlink zum „vorherigen“ bzw. „nächsten“ Bild entfernt (das es ja keine gibt).
Die Bilder stammen alle von meinem Blog und somit sind diese natürlich für dich frei zur Verwendung in diesem Beitrag.
analysieren des HTML Grundgerüsts
Schauen wir uns nun das HTML Grundgerüst (auch DOM genannt) an. Denn wir müssen ja wissen welche Attribute an den HTML Tags existieren. Wir starten mit der Seite „../index.html“, diese Seite wird immer geladen wenn wir nur die Adresse „img.crawl.draeger-it.blog“ eingeben.
Den Quelltext einer Webseite können wir uns in jedem Browser über das Kontextmenü anzeigen lassen. Der Eintrag heißt natürlich bei jedem Browser etwas anders.
Ich nutze für diesen Beitrag den Browser Google Chrome.
Der Inhalt der Seite „index.html“ wird in einem neuen Tab angezeigt und formatiert dargestellt.
<html>
<link rel="stylesheet" type="text/css" href="styles.css"/>
<body>
<div class="topNavi">
<a class="pageLink active" href="./index.html">Home</a>
<a class="pageLink" href="./page1.html">1</a>
<a class="pageLink" href="./page2.html">2</a>
<a class="pageLink" href="./page3.html">3</a>
</div>
<table>
<tbody>
<tr>
<td>
<a class="imgLink" href="img1.html"><img src="./img/1.jpg" width="100"/></a>
<br/>
<span>1.jpg</span>
</td>
<td>
<a class="imgLink" href="img2.html"><img src="./img/2.jpg" width="100"/></a>
<br/>
<span>2.jpg</span>
</td>
<td>
<a class="imgLink" href="img3.html"><img src="./img/3.jpg" width="100"/></a>
<br/>
<span>3.jpg</span>
</td>
</tr>
</tbody>
</table>
<div class="bottomNavi">
<a class="pageLink active" href="./index.html">Home</a>
<a class="pageLink" href="./page1.html">1</a>
<a class="pageLink" href="./page2.html">2</a>
<a class="pageLink" href="./page3.html">3</a>
</div>
</body>
</html>
Wir sehen also das es zwei verschiedene Hyperlinks auf der Seite gibt. Einmal ein Hyperlink mit der CSS-Klasse „pageLink“ und zum anderen mit „imgLink“. Die Hyperlinks mit der CSS-Klasse „pageLink“ verweisen auf eine neue Seite und die Hyperlinks mit „imgLink“ auf die Unterseite zu dem großen Bild.
D.h. wir müssen uns als nächstes die Unterseite mit dem großen Bild anschauen.
<html>
<link rel="stylesheet" type="text/css" href="styles.css"/>
<body>
<div class="topNavi">
<a class="pagelink" href="./index.html" />Home</a><a class="pagelink" href="img1.html" />vorheriges</a><a class="pagelink" href="img3.html" />nächstes</a>
</div>
<div class="container">
<img src="./img/2.jpg" />
</div>
<div class="bottomNavi">
<a class="pagelink" href="./index.html" />Home</a><a class="pagelink" href="img1.html" />vorheriges</a><a class="pagelink" href="img3.html" />nächstes</a>
</div>
</body>
</html>
Python3 Skript
In diesem Abschnitt des Beitrages möchte ich dir nun zeigen wie du Schritt für Schritt das Skript zum laden von Bilder aus dem Internet erstellen kannst. Die einzelnen Tätigkeiten des Skrips werden dabei in einzelne Funktionen ausgelagert.
Importieren der Bibliotheken
Damit wir auf die verschiedenen Funktionen der oben genannten Bibliotheken zugreifen können müssen wir diese importieren. Hierzu habe ich bereits den Beitrag Python #18: laden von Modulen erstellt und dort ausführlich das Thema behandelt.
#für den Zugriff auf HTML Inhalte (Tags, Klassen, Bilder usw.) from bs4 import BeautifulSoup #für den Zugriff auf Resourcen aus dem Internet / Intranet (HTML Seiten, Bilder, Videos usw.) import requests #für das korrekte zusammensetzen einer Url mit einer Adresse einer Resource from urllib.parse import urljoin #für das speichern einer Datei auf der Festplatte from urllib.request import urlopen #für das extrahieren des Dateinamens aus einer Url from os.path import basename #für das erstellen von Verzeichnissen import os
Schritt 1 – laden der ersten Seite
Im ersten Schritt laden wir uns den Inhalt der Startseite und holen uns alle Links von Bilder (CSS-Klasse .imgLink). An jedem Hyperlink (Tag ‚a‘) existiert das Attribut „href“ welches die Zieladresse des Links repräsentiert. Jedoch ist diese in der Regel nicht absolut sondern relativ, d.h. die Adresse startet mit einem „.“ hier hilft uns das Modul „urllib“ mit der Funktion „urljoin“ weiter. Der Funktion „urljoin“ wird die Adresse übergeben und die relative Adresse der Resource und daraus wird die korrekte Adresse gemappt.
Zum Schluss wird die gemappte Url in eine Liste aufgenommen um später weiterverarbeitet zu werden.
def fetchUrls(url):
r = requests.get(url)
document = BeautifulSoup(r.content, "html.parser")
#holen der Hyperlinks mit den Links zu Unterseiten zu Bildern
for link in document.select(".imgLink"):
#speichern des Links
urls.append(urljoin(url, link.attrs['href']))
Schritt 2 – laden der weiteren Seiten
Der zweite Schritt ist immernoch in der Funktion „fetchUrls“ und kommt nach dem dem laden Hyperlinks von den Bildern. Es gibt in unserem Beispiel zwei Navigationsbereiche „topNavi“ & „bottomNavi“. Beide Navigationsbereiche enthalten die gleichen Ziele daher prüfen wir zusätzlich ob der Link bereits in der Liste der Urls enthalten ist. Da die Seiten alle gleich aufgebaut sind starten wir die Funktion „fetchUrls“ mit dem Parameter der neuen Adresse (recursives abarbeiten der Seite).
def fetchUrls(url):
...
#holen der Hyperlinks mit den Links zu nächsten Seiten
pageLinks = document.select(".pageLink")
for pageLink in pageLinks:
#zusammenfügen des Links
pageUrl = urljoin(url, pageLink.attrs["href"])
#Wenn die Seite NICHT bekannt ist, quasi noch nicht in die Liste aufgenommen wurde, dann...
if pageUrl not in urls:
#Link der Liste hinzufügen
urls.append(pageUrl)
#recursives lesen des Links
fetchUrls(pageUrl)
Schritt 3 – crawlen der Seiten mit den großen Bildern
Nachdem wir nun alle Adressen der Unterseiten mit den großen Bildern ermittelt und in einer Liste gesammelt haben müssen wir dort nun die Adressen der Bilder ermitteln. Mit der Funktion „find_all“ und dem Parameter „img“ holen wir uns alle Img Tags auf der Seite. In unserem Beispiel existiert pro Seite eigentlich nur ein Bild und somit enthält die Liste nur einen Eintrag. Wir könnten also auch gut die Funktion „find_one“ verwenden und die Schleife verwerfen.
Die Adresse des großen Bildes wird in die Liste „imageUrls“ aufgenommen.
def crawlUrls(urls):
#für jede gefundene Url mache...
for url in urls:
#content laden
r = requests.get(url)
document = BeautifulSoup(r.content, "html.parser")
#alle Bilder finden (Tag mit img)
images = document.find_all("img")
for image in images:
#lesen des Attributes "src"
imageSource = image.attrs["src"]
#zusammenfügen des kurzen "src" Links mit der Url
hyperlink = urljoin(url, imageSource)
#wenn der Link zum Bild NICHT in der Liste der Bilder ist dann...
#somit kann man relativ einfach duplikate herausfiltern
if hyperlink not in imageUrls:
imageUrls.append(hyperlink)
Schritt 4 – laden der Bilder und speichern auf der Festplatte
Im vierten und letzten Schritt laden wir die Bilder aus dem Internet auf unsere Festplatte.
def loadImages(imageUrls):
#für jeden gefundenen Hyperlink zu einem Bilde mache...
for imageUrl in imageUrls:
#extrahieren des Dateinamens
filename = basename(imageUrl)
#ermitteln des Dateinamens
targetFile = targetDirectory+"/"+filename
#Wenn der Dateiname noch nicht existiert dann...
if not os.path.exists(targetFile):
#ausgeben der Adresse auf der Konsole
print("lade Bild "+imageUrl)
#laden des Bildes auf der Festplatte
urllib.request.urlretrieve(imageUrl, targetFile)
else: #Wenn die Datei bereits existiert, wird folgende Meldung ausgegeben
print("Datei", targetFile, "existiert bereits!")
Im nachfolgenden findest du nun das Skript welches die Webseite analysiert und die Bilder auf der Festplatte speichert.
from bs4 import BeautifulSoup
import requests
from urllib.parse import urljoin
from urllib.request import urlopen
from os.path import basename
import os
url = "https://img.crawl.draeger-it.blog/"
urls = []
imageUrls = []
targetDirectory = "images123"
#initialisieren des Skriptes
#hier wird zbsp. der Ordner angelegt
#wo die Bilder später abgelegt werden
def init():
if not os.path.exists(targetDirectory):
os.mkdir(targetDirectory)
#recursives lesen der Urls
def fetchUrls(url):
r = requests.get(url)
document = BeautifulSoup(r.content, "html.parser")
#holen der Hyperlinks mit den Links zu Unterseiten zu Bildern
for link in document.select(".imgLink"):
#speichern des Links
urls.append(urljoin(url, link.attrs['href']))
#holen der Hyperlinks mit den Links zu nächsten Seiten
pageLinks = document.select(".pageLink")
for pageLink in pageLinks:
#zusammenfügen des Links
pageUrl = urljoin(url, pageLink.attrs["href"])
#Wenn die Seite NICHT bekannt ist, quasi noch nicht in die Liste aufgenommen wurde, dann...
if pageUrl not in urls:
#Link der Liste hinzufügen
urls.append(pageUrl)
#recursives lesen des Links
fetchUrls(pageUrl)
#liest die Bilder aus einer Url
def crawlUrls(urls):
#für jede gefundene Url mache...
for url in urls:
#content laden
r = requests.get(url)
document = BeautifulSoup(r.content, "html.parser")
#alle Bilder finden (Tag mit img)
images = document.find_all("img")
for image in images:
#lesen des Attributes "src"
imageSource = image.attrs["src"]
#zusammenfügen des kurzen "src" Links mit der Url
hyperlink = urljoin(url, imageSource)
#wenn der Link zum Bild NICHT in der Liste der Bilder ist dann...
#somit kann man relativ einfach duplikate herausfiltern
if hyperlink not in imageUrls:
imageUrls.append(hyperlink)
#speichern der Bilder auf der Festplatte
def loadImages(imageUrls):
#für jeden gefundenen Hyperlink zu einem Bilde mache...
for imageUrl in imageUrls:
#extrahieren des Dateinamens
filename = basename(imageUrl)
#ermitteln des Dateinamens
targetFile = targetDirectory+"/"+filename
#Wenn der Dateiname noch nicht existiert dann...
if not os.path.exists(targetFile):
#ausgeben der Adresse auf der Konsole
print("lade Bild "+imageUrl)
#laden des Bildes auf der Festplatte
urllib.request.urlretrieve(imageUrl, targetFile)
else: #Wenn die Datei bereits existiert, wird folgende Meldung ausgegeben
print("Datei", targetFile, "existiert bereits!")
init()
fetchUrls(url)
crawlUrls(urls)
loadImages(imageUrls)
Letzte Aktualisierung am: 26. Mai 2025

Hallo ,
ich ahbe dein Programm ausprobiert alles funktioniert nur bei den Befehl urllib.request.urlretrieve(imageUrl, targetFile)
bekomme ich die Fehlermeldung
NameError: name ‚urllib‘ is not defined
Wenn du eine Idee hast warum es nicht funktioniert währe ich für eine Lösung dankbar
Hi,
du musst die entsprechende Bibliothek installieren. Ich verwende upyther Notebook in Anakonda und da ist schon sehr viel dabei.
Gruß,
Stefan Draeger