In diesem Tutorial möchte ich beschreiben, wie man in einer JavaServerFaces Webanwendung Daten in einer Datenbank mit Eclipselink speichert.
Als Grundlage für dieses Tutorial möchte ich das Projekt „Timeline“ verwenden, dieses Projekt habe ich bereits im Tutorial Erstellen einer Timeline für Beiträge mit JavaServerFaces vorgestellt.
Zum Speichern der Daten verwende ich eine H2 Datenbank. Diese ist relativ schlank und kommt ohne eine Installation daher. Somit ist diese Datenbank gut für die Entwicklung geeignet. Im späteren Betrieb kann der Datenbanktreiber und die entsprechende Konfiguration einfach über XML angepasst werden.
erweitern der Maven Dependencies
Damit wir Eclipselink konfigurieren und später verwenden können, müssen wir uns zunächst die Abhängigkeiten in das Projekt holen. Da das Projekt mit Apache Maven aufgebaut ist, wird die Datei „pom.xml“ wie folgt ergänzt.
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.7.0</version>
<exclusions>
<exclusion>
<groupId>org.eclipse.persistence</groupId>
<artifactId>javax.persistence</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>javax.persistence</artifactId>
<version>2.1.1</version>
</dependency>
Wie bereits erwähnt verwende ich für dieses Tutorial eine H2 Datenbank, daher benötige ich zusätzlich die Abhängigkeit, um den Treiber zu laden. Wenn Sie eine andere Datenbank zbsp. Apache Derby, MySQL verwenden wollen benötigen Sie den entsprechenden Treiber.
<dependency> <groupId>com.h2database</groupId> <artifactId>h2</artifactId> <version>1.4.199</version> </dependency>
erweitern der Verzeichnisstruktur
Neben den Abhängigkeiten benötigen wir noch zusätzlich das Verzeichnis „META-INF“ und die Datei „persistence.xml“. Das Verzeichnis wird unter
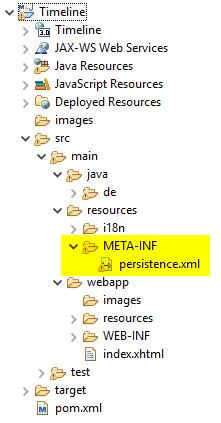
einrichten der Datei „persistence.xml“
In der Datei „persistence.xml“ wird die Einstellung für die Datenbankverbindung gesetzt. Hier gibt es 2 Arten von Verbindungen,
- direkte JDBC Connection und
- Container-managed Datasource
Für dieses Tutorial verwende ich zunächst eine „direkte JDBC Connection“. Da die Anwendung in einem Apache Tomcat läuft und dieser Server kein EE kann lohnt sich der Weg über die „Container-managed Datasource“ nicht.
<?xml version="1.0" encoding="UTF-8" ?> <persistence xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd" version="2.0" xmlns="http://java.sun.com/xml/ns/persistence"> <persistence-unit name="timeline" transaction-type="RESOURCE_LOCAL"> </persistence-unit> </persistence>
Zunächst einmal muss man der Verbindung einen Namen geben, dieser wird im Attribut „name“ gesetzt.
Der Name muss einzigartig / unique in der Datei „persistence.xml“ sein.
Im Attribut „transaction-type“ wird in diesem Beispiel „RESOUCE_LOCAL“ gesetzt, wenn eine „Container-managed Datasource“ verwendet dann muss dort „JTA“ eingetragen werden.
Erweitern der Klasse TimelineEntry
Die Klasse „TimelineEntry“ ist aus dem Tutorial Erstellen einer Timeline für Beiträge mit JavaServerFaces bekannt.
Damit wir diese in der Datenbank speichern können, müssen wir die Klasse mit der Annotation @Entity annotieren sowie das Interface Serializable implementieren.
Zusätzlich müssen wir ein Feld für die ID implementieren denn dieses wird als Primaryfield für die spätere Tabelle benötigt.
@Entity(name = "Timeline")
@Table(name = "Timeline")
public class TimelineEntry implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private long id;
public long getId() { return id; }
public void setId(long id) { this.id = id; }
}
Einbinden als Entity
Damit diese javax.persistence.Entity vom EntityManager gefunden wird, muss diese Klasse in der Datei „persistence.xml“ deklariert werden.
<persistence-unit name="timeline" transaction-type="RESOURCE_LOCAL"> <class>de.draegerit.timeline.entity.TimelineEntry</class>
Data Access Object Pattern
Als nächsten Schritt wollen wir unsere DAO für das Speichern der Entity erstellen. DAO bedeutet „Data Access Object“ und dahinter versteckt sich ein Pattern zum serialisieren von Daten. Dabei ist es nicht unbedingt vonnöten diese Daten in eine Datenbank zu speichern, auch für XML oder JSON Daten kann dieses Pattern angewendet werden.
Zunächst einmal benötigen wir ein Interface „Dao“ mit den Methoden welche für das speichern und laden von Daten benötigt werden.
import java.util.List;
public interface Dao<T> {
T get(long id);
List<T> getAll();
void save(T t);
void update(T t, String[] params);
void delete(T t);
}
Da die Methode „save(T t)“ für jede Entity gleich ist, erstelle ich eine abstrakte Klasse welche das Interface „Dao“ implementiert. Zusätzlich kann man hier einmalig die Factory für den EntityManager definieren und erspart sich hier auch wieder doppelten Code.
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public abstract class AbstractDao<T> implements Dao<T> {
protected EntityManagerFactory factory;
private static final String PERSISTENCE_UNIT_NAME = "timeline";
public AbstractDao() {
factory = Persistence.createEntityManagerFactory(PERSISTENCE_UNIT_NAME);
}
@Override
public void save(T t) {
EntityManager em = factory.createEntityManager();
em.getTransaction().begin();
em.persist(t);
em.getTransaction().commit();
em.close();
}
}
Des Weiteren implementieren wir eine Methode, welche uns eine Liste aller Entitys für den generischen Typ liefert. Dieser Methode wird der Name einer NamedQuery übergeben.
public List<T> findAllEntitys(String namedQuery){
EntityManager em = factory.createEntityManager();
em.getTransaction().begin();
List<T> resultList = em.createNamedQuery(namedQuery).getResultList();
em.getTransaction().commit();
em.close();
return resultList;
}
Zum Schluss müssen wir uns noch eine Klasse „TimelineEntryDAO“ anlegen, welche die abstrakte Klasse „AbstractDao“ erweitert. Als generischen Typ übergebe ich die Entity „TimelineEntry“.
import java.util.List;
public class TimelineEntryDAO extends AbstractDao<TimelineEntry> {
@Override
public TimelineEntry get(long id) { return null; }
@Override
public List<TimelineEntry> getAll() { return null; }
@Override
public void update(TimelineEntry t, String[] params) { }
@Override
public void delete(TimelineEntry t) { }
}
Nun müssen wir noch unsere Klasse „TimelineEntry“ um die NamedQuery erweitern
@NamedQuery(name = "findAllTimelineEntries", query = "SELECT t FROM Timeline t")
public class TimelineEntry implements Serializable {
und die Methode „getAll()“ wiefolgt ausprogrammieren
@Override
public List<TimelineEntry> getAll() {
return findAllEntitys("findAllTimelineEntries");
}
Da der Name einer NamedQuery unique quasi einziartig sein muss, kann man diese nicht gleich benennen und generisch verwenden.
JUnit Testfall
Um die Funktionalitäten des Speicherns und Ladens einer Entity zu testen verwende ich einen JUnit Testfall.
Speichern eines TimelineEntrys
public class JPATimelineEntryTest {
@Test
public void storeEntity() {
TimelineEntry entry = new TimelineEntry();
entry.setText("Hallo Welt!");
entry.setTimestamp(System.currentTimeMillis());
entry.setTitle("Titel - 123");
TimelineEntryDAO dao = new TimelineEntryDAO();
dao.save(entry);
}
}
SQL Client SQuirreL
Wenn die ersten Daten in der H2 Datenbank gespeichert wurden, kann man sich diese mit einem SQL Client anschauen. Ich verwende im nachfolgenden den SQL Client SQuirreL. (Dieser SQL Client ist kostenfrei erhältlich.)
Installation
Der SQL Client kann von SourceForge kostenfrei geladen werden. Ich verwende das Paket „https://sourceforge.net/projects/squirrel-sql/files/latest/download“ dieses wird in einen beliebigen Ordner heruntergeladen und per doppelklick gestartet.
Schritt 1 – Starten des Wizards
Mit einem doppelklick auf die Datei „squirrel…jar“ wird der Wizard zum Installieren des SQL Clients gestartet.
Nachdem man die kurze Einleitung gelesen hat, bestätigt man dieses Fenster mit der Schaltfläche „Next“. Im nachfolgenden Fenster wird auf die Systemvoraussetzung der jeweiligen Version von Squirell hingewiesen.
Auch dieses Fenster bestätigen wir mit der Schaltfläche „Next“.
Sollte eine kleinere Version von Oracle Java installiert sein als benötigt so sollte der Wizard hier unterbrochen werden und dieses nachgeholt werden.
Schritt 2 – Zielverzeichnis wählen
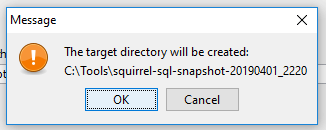
Im nächsten Fenster wird das Zielverzeichnis gewählt. Ich weiche hier vom vorgegebenen Verzeichnis ab.

Sollte das Verzeichnis nicht existieren, so wird man in einem zusätzlichen Dialog gefragt, ob das Verzeichnis erstellt werden soll. Diesen Dialog sollte man zunächst mit „OK“ bestätigen.
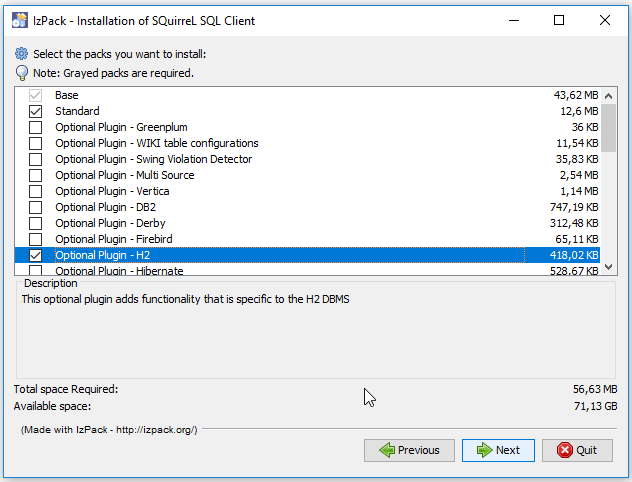
Schritt 3 – Installationspakete wählen
Im nachfolgenden Schritt werden nun die Installationspakete ausgewählt, da ich für dieses Tutorial die H2 Datenbank verwende, wähle ich das zusätzliche, optionale Plug „H2“ aus und bestätige die Auswahl mit der Schaltfläche „Next“.
Nachdem nun das Zielverzeichnis und die Installationspakete gewählt wurden, wird der SQL Client installiert.
Wurde die Installation erfolgreich fertiggestellt, so muss dieses Fenster mit der Schaltfläche „Next“ bestätigt werden.
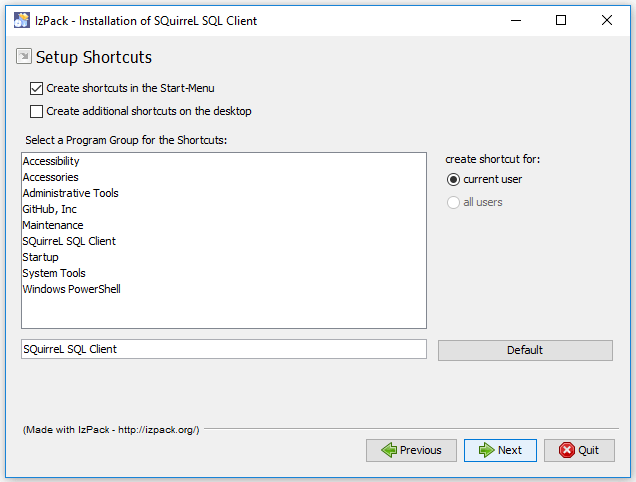
Schritt 4 – Shortcuts setzen
Abschließend kann man optional Shortcuts erstellen lassen. Ich belasse die gesetzten Einstellungen und bestätige dieses Fenster mit der Schaltfläche „Next“.
Schritt 5 – Abschluss der Installation
Im letzten Schritt 5 wird die Installation abgeschlossen, es wird ein kurzer Text angezeigt, dass die Installation erfolgreich war und auf den uninstaller hingewiesen. Dieses Fenster kann nur mit einem klick auf der „X“ oben rechts geschlossen werden.

Einrichten der TimelineDB
Kopieren des H2 Datenbanktreibers
Damit man in dem SQL Client eine Verbindung zur Datenbank einrichten kann benötigt man den Treiber. Diesen Treiber haben wir mit dem Apache Maven Projekt bereits aus dem Internet geladen und finden diesen unter C:\Benutzer\<<Benutzername>>\.m2\repository\com\h2database\h2\<<Versionsnummer>>\h2-<<Versionsnummer>>.jar.
Der Treiber kann dann optional von dort geladen werden oder aber in den Ordner „libs“ der SQuirreL installation kopieren. In diesem Tutorial kopiere ich den Treiber in das „lib“ Verzeichnis, dieses hat den Vorteil, dass man den Treiber nicht extra installieren muss, da dieser beim Starten der Anwendung SQuirreL geladen wird.
Starten von SQuirreL
Wurde der SQL Client SQuirreL erfolgreich installiert, so wird dieser über die Datei „squirrel-sql.bat“ oder dem zur vor Erstellen Shortcut gestartet.
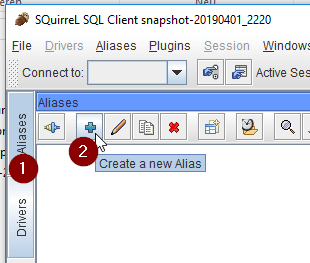
Erstellen eines Aliases für die Datenbankverbindung
Zunächst einmal muss man auf den Reiter „Aliases“ (1) wechseln und danach die Schaltfläche „Create a new Alias“ (2) betätigen.
Im nachfolgenden Dialog geben wir diesem Alias einen Namen und setzen den Benutzernamen (User Name) sowie das Passwort.
Die URL kann man aus der Datei „persistence.xml“ entnehmen, jedoch muss man den Pfad anpassen, denn „./“ bezieht sich immer auf das aktuelle Verzeichnis.
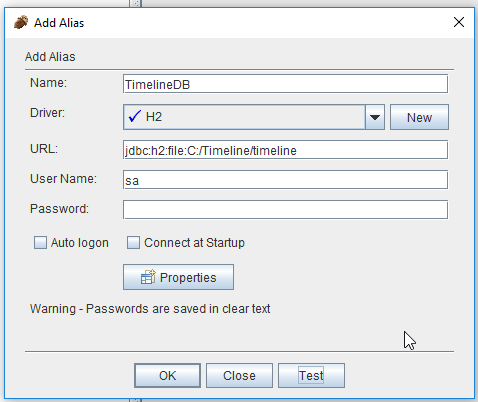
In diesem Fenster kann man die Einstellungen testen, indem man einfach auf die Schaltfläche „Test“ klickt und im nachfolgenden Fenster ggf. Benutzername & Passwort eingibst.
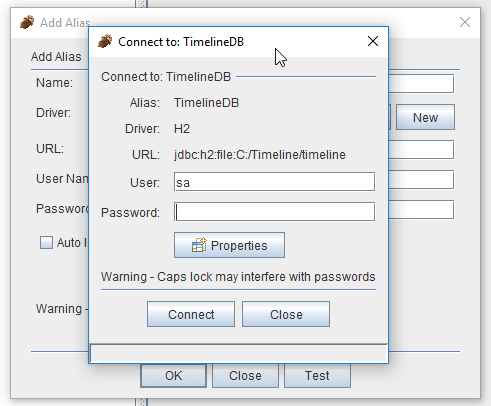
Ist dieses erfolgt, so kann eine Verbindung mit der Schaltfläche „Connect“ aufgebaut werden.
Aufbau der Verbindung
Wenn die Datenbankverbindung eingerichtet ist, kann diese im Reiter „Aliases“ mit einem Doppelklick gestartet werden.

Letzte Aktualisierung am: 26. Mai 2023
