Im letzten Beitrag habe ich dir gezeigt, wie du in Node-RED unter Docker eine SQLite-Datenbank anbindest und über ein Formular erste Daten bequem in die Datenbank schreiben kannst. Genau auf diesem Aufbau setzen wir nun auf und erweitern den bestehenden Flow um eine praktische Funktion: den Versand eines Newsletters.
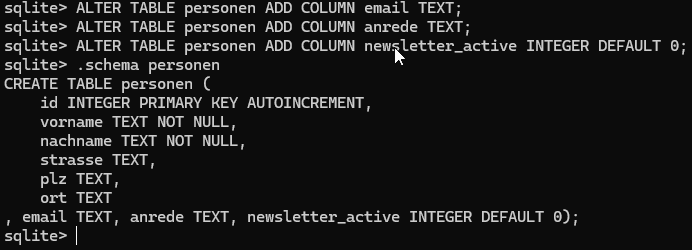
Dafür lesen wir Daten aus einer CSV-Datei ein, speichern diese in der Datenbank und nutzen die hinterlegten Informationen anschließend, um E-Mails gezielt an Empfänger zu versenden. Damit das sauber funktioniert, muss unsere bestehende Tabelle zunächst um zwei zusätzliche Spalten erweitert werden: eine für die E-Mail-Adresse und eine weitere, um festzuhalten, ob der Newsletter für diesen Kontakt aktiv ist.
So schaffen wir die Grundlage, um in Node-RED einen einfachen Newsletter-Workflow aufzubauen, der auf bereits vorhandenen Daten aufsetzt und sich gut erweitern lässt.

So funktioniert der Newsletter-Flow in Node-RED
Ziel dieses Beitrags ist es, einen einfachen Newsletterversand mit Node-RED umzusetzen. Der große Vorteil dabei: Du musst keine klassische Programmierung beherrschen, da wir ausschließlich mit visuellen Funktionsblöcken arbeiten und diese zu einem funktionierenden Flow verbinden.
Das Szenario ist bewusst praxisnah gewählt:
Du erhältst beispielsweise eine Excel-Liste mit Kontaktdaten (z. B. aus dem Vertrieb) sowie einen vorbereiteten Newsletter-Text mit Platzhaltern wie Vorname, Nachname oder Anrede.
Der Ablauf des Workflows sieht dabei wie folgt aus:
- Die Excel-Datei wird als CSV exportiert und in Node-RED importiert
- Die enthaltenen Daten werden in einer SQLite-Datenbank gespeichert
- Per Knopfdruck wird der Newsletter-Versand gestartet
- Es werden nur Kontakte berücksichtigt, bei denen der Newsletter aktiv ist
- Der Newsletter wird personalisiert (z. B. „Hallo Max“) versendet
Ein wichtiger Bestandteil eines jeden Newsletters ist außerdem die Möglichkeit zur Abmeldung.
Daher enthält jede E-Mail einen Abmelde-Link, über den sich Empfänger einfach aus dem Verteiler austragen können. Im Hintergrund wird dabei der entsprechende Datensatz automatisch deaktiviert.
Mit diesem Ansatz entsteht ein einfacher, aber flexibler Newsletter-Workflow, der sich beliebig erweitern lässt und komplett lokal betrieben werden kann.
Datenbasis vorbereiten
Als Grundlage für unseren Newsletter benötigen wir zunächst eine einfache Liste mit Kontaktdaten. In der Praxis erhält man diese häufig als Excel-Datei (XLSX), zum Beispiel aus dem Vertrieb oder einem CRM-System.
Da Node-RED CSV-Dateien sehr gut verarbeiten kann, wird die Excel-Datei im ersten Schritt als CSV-Datei exportiert. Das funktioniert in Excel mit wenigen Klicks („Speichern unter“ → CSV-Format).
Unsere CSV-Datei enthält folgende Spalten:
Vorname;Nachname;Anrede;Strasse;Postleitzahl;Ort;E-Mail Adresse;Newsletter aktivDiese Struktur bildet die Grundlage für unseren späteren Newsletter-Versand.
- Vorname / Nachname → für die Personalisierung
- Anrede → z. B. „Herr“ oder „Frau“
- E-Mail Adresse → Zieladresse für den Versand
- Newsletter aktiv → steuert, ob ein Kontakt angeschrieben wird (1 = aktiv, 0 = deaktiviert)
Vorname;Nachname;Anrede;Strasse;Postleitzahl;Ort;E-Mail Adresse;Newsletter aktiv
Max;Mustermann;Herr;Musterstraße 1;10115;Berlin;max.mustermann@example.com;1
Anna;Schmidt;Frau;Hauptstraße 12;20095;Hamburg;anna.schmidt@example.com;1
Peter;Müller;Herr;Gartenweg 5;80331;München;peter.mueller@example.com;0
Lisa;Fischer;Frau;Bahnhofstraße 22;50667;Köln;lisa.fischer@example.com;1
Thomas;Weber;Herr;Schillerstraße 8;70173;Stuttgart;thomas.weber@example.com;0Wichtig: Die CSV-Datei verwendet in unserem Fall ein Semikolon (;) als Trennzeichen, was insbesondere im deutschen Excel-Umfeld üblich ist.
Im nächsten Abschnitt werden wir die Datenbank entsprechend vorbereiten. Dabei fügen wir die benötigten Felder für Anrede, E-Mail-Adresse und den Newsletter-Status hinzu, damit diese Informationen später im Flow verarbeitet werden können.
Datenbank erweitern
Damit wir die zusätzlichen Informationen aus der CSV-Datei verarbeiten können, müssen wir unsere bestehende Tabelle in der SQLite-Datenbank erweitern. Konkret fügen wir drei neue Spalten hinzu:
- Anrede
- E-Mail Adresse
- Newsletter aktiv
Dies kann entweder direkt über die Bash erfolgen oder alternativ einmalig über einen Node-RED Flow.
Variante 1: Erweiterung per SQL (Bash)
Die einfachste Möglichkeit ist, die Tabelle über ein ALTER TABLE Statement zu erweitern:
ALTER TABLE personen ADD COLUMN anrede TEXT; ALTER TABLE personen ADD COLUMN email TEXT; ALTER TABLE personen ADD COLUMN newsletter_active INTEGER DEFAULT 0;
Hinweis:
newsletter_activewird als Integer gespeichert (0 = deaktiviert, 1 = aktiv)- Ein Default-Wert verhindert Probleme bei bestehenden Datensätzen
Variante 2: Erweiterung über Node-RED
Alternativ kannst du die SQL-Statements auch über einen kleinen Flow in Node-RED ausführen:
- Inject-Node (einmalig auslösen)
- Function-Node (setzt das SQL Statement in
msg.topic) - SQLite-Node (führt das Statement aus)

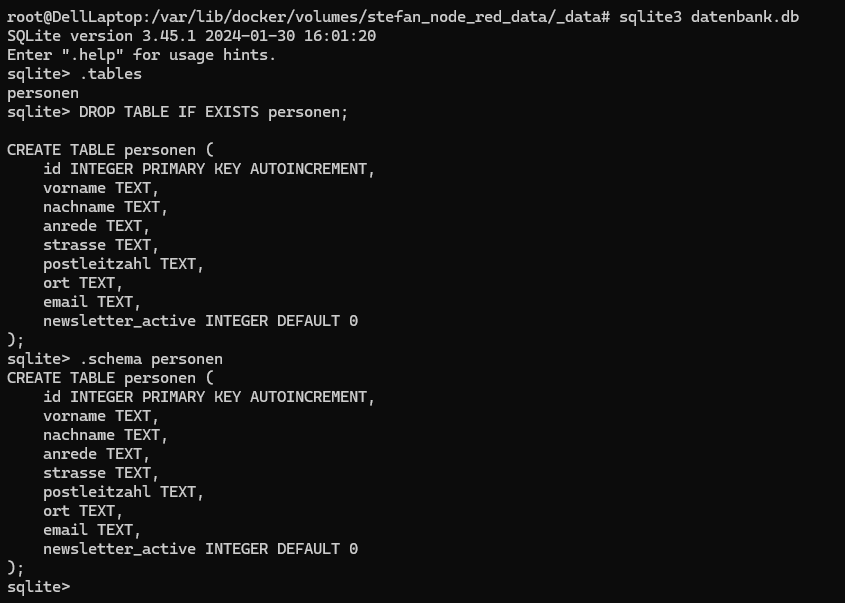
Variante 3: Tabelle neu erstellen (CREATE TABLE)
Falls du direkt mit diesem Beitrag startest, kannst du die Tabelle auch komplett neu anlegen:
DROP TABLE IF EXISTS personen;
CREATE TABLE personen (
id INTEGER PRIMARY KEY AUTOINCREMENT,
vorname TEXT,
nachname TEXT,
anrede TEXT,
strasse TEXT,
postleitzahl TEXT,
ort TEXT,
email TEXT,
newsletter_active INTEGER DEFAULT 0
);
Damit hast du direkt die komplette Struktur für unseren Newsletter-Flow vorbereitet.
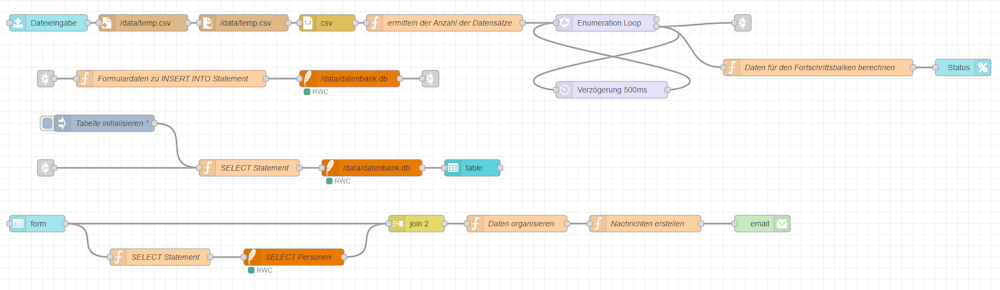
CSV in Node-RED einlesen
Da ein Newsletter in der Regel nicht nur einmal versendet wird, sondern regelmäßig neue Empfängerlisten eingelesen werden sollen, bietet sich für diesen Schritt eine möglichst einfache und flexible Lösung an. Besonders praktisch ist hier ein Formular im Node-RED Dashboard, über das die CSV-Datei bequem hochgeladen werden kann.
Der große Vorteil:
Die Datei kann direkt über die Oberfläche bereitgestellt werden, ohne dass man sich mit dem Dateisystem des Hosts oder des Docker-Containers beschäftigen muss. Das macht den Workflow nicht nur komfortabler, sondern auch deutlich flexibler im täglichen Einsatz.

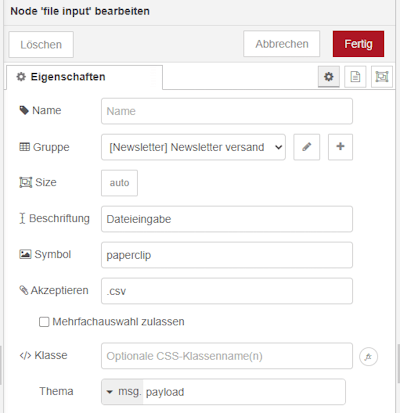
Schritt 1 – File Input Node für den Dateiupload
Der Start für den Flow ist eine file input Node welche nur CSV Dateien akzeptiert. Der Inhalt der Datei wird im Feld msg.payload ablegt.

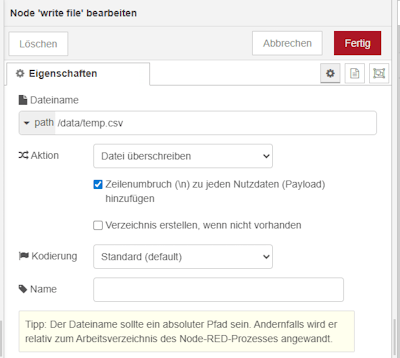
Schritt 2 – ablegen der CSV-Datei auf den Raspberry Pi
Die hochgeladene Datei wird aus dem Formular entnommen und anschließend auf dem Raspberry Pi gespeichert. In meinem Fall erfolgt die Ablage im Verzeichnis _data innerhalb des Docker-Containers.

Schritt 3 – lesen der CSV-Datei
Die gespeicherte Datei kann nun mit einer Read File Node erneut eingelesen werden. Dadurch stellen wir sicher, dass immer der zuletzt hochgeladene Datenstand verfügbar ist.
Zusätzlich dient die abgelegte CSV-Datei als einfache Sicherung auf dem Raspberry Pi, sodass die Daten auch unabhängig vom aktuellen Flow erhalten bleiben.

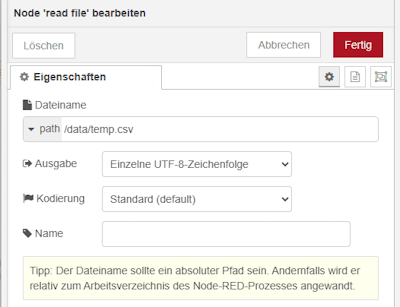
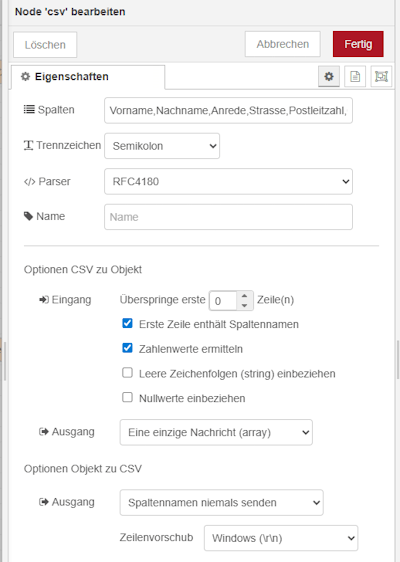
Schritt 4 – Transformieren der Daten in das CSV-Format
Die eingelesenen Daten müssen anschließend in ein strukturiertes Format überführt werden. Dafür verwenden wir die CSV-Node in Node-RED.
In der Konfiguration definieren wir zunächst die Spaltennamen (kommagetrennt), sodass die Daten korrekt den jeweiligen Feldern zugeordnet werden können. Zusätzlich geben wir an, dass die Werte in der Datei durch ein Semikolon (;) getrennt sind.
Da unsere CSV-Datei eine Kopfzeile enthält, aktivieren wir außerdem die Option, dass die erste Zeile als Spaltenüberschrift interpretiert wird.
Als Ausgabeformat wählen wir ein Array von Objekten. Dadurch steht jeder Datensatz als eigenes Objekt zur Verfügung und kann im nächsten Schritt einfach über eine Loop-Node weiterverarbeitet werden.

Schritt 5 – ermitteln der Anzahl der Datensätze
Für die Statusanzeige beim Import der Daten benötigen wir die Anzahl der Datensätze. Diese lässt sich ganz einfach mit einer kleinen Function-Node ermitteln.
Da die CSV-Daten bereits als Array vorliegen, können wir die Anzahl der Elemente direkt über die Länge des Arrays bestimmen. Dafür reicht ein kurzer JavaScript-Zweizeiler:

msg.data_size = msg.payload.length; return msg;
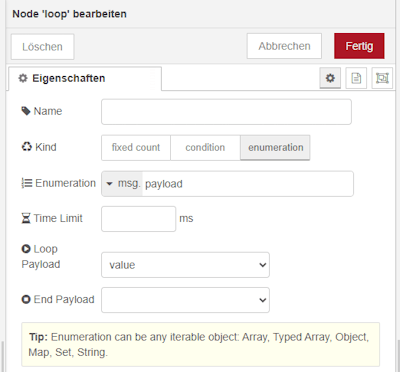
Schritt 6 – Loop über die Daten
Der Vorteil der Datenstruktur als Array ist, dass wir die einzelnen Datensätze komfortabel über eine Loop-Node nacheinander verarbeiten können.
Wichtig dabei ist, dass der Flow nach der Verarbeitung eines Datensatzes wieder an den Anfang der Loop zurückgeführt wird, damit alle Einträge vollständig abgearbeitet werden.
In meinem Beispiel baue ich zusätzlich eine Verzögerung von 500 ms zwischen den einzelnen Durchläufen ein. Dadurch wird der nachgelagerte Flow, insbesondere die Datenbankzugriffe, etwas entlastet. Gleichzeitig hat dies den positiven Effekt, dass der Fortschritt in der Balkenanzeige sichtbar und nachvollziehbar wird.


Schritt 7 – Daten für den Fortschrittsbalken berechnen
Der Fortschrittsbalken arbeitet mit Werten zwischen 0 und 100 Prozent. Da wir zuvor bereits die Gesamtanzahl der Datensätze ermittelt haben, können wir den Fortschritt nun anteilig berechnen.
Dafür nutzen wir den aktuellen Index der Loop (Achtung: dieser startet bei 0) sowie die maximale Anzahl der Datensätze. Aus diesen beiden Werten lässt sich der Fortschritt pro Schritt einfach berechnen – im Grunde eine klassische Prozentrechnung.
Das berechnete Ergebnis wird anschließend in msg.payload geschrieben und steuert damit den Fortschrittsbalken.
Zusätzlich definieren wir über msg.ui_update das Erscheinungsbild, beispielsweise den Text und die Farbe der Anzeige.
let steps = 100 / msg.data_size;
// Fortschritt berechnen (index startet meist bei 0!)
msg.payload = (msg.loop.index + 1) * steps;
msg.ui_update = {
label: "importiere Daten",
color: "info"
};
return msg;
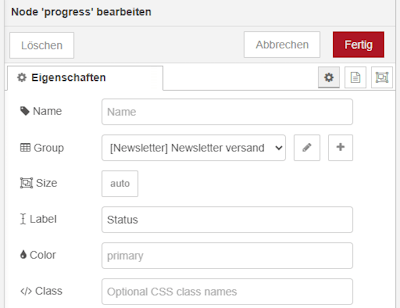
Schritt 8 – Fortschrittsbalken
Der Fortschrittsbalken selbst benötigt keine weitere Konfiguration. Er erwartet lediglich einen Wert zwischen 0 und 100 im Feld msg.payload, der den aktuellen Fortschritt repräsentiert.
Sobald dieser Wert gesetzt wird, aktualisiert sich die Anzeige automatisch im Dashboard.

Schritt 9 – Starten eines Subflows
Der eigentliche Import der Daten wird in einen Subflow ausgelagert. Dadurch bleibt der aktuelle Flow übersichtlich und die einzelnen Aufgaben sind klar voneinander getrennt.
Ein weiterer großer Vorteil ist die Wiederverwendbarkeit: Bestehende Logik, wie beispielsweise das spätere Aktualisieren der Tabelle, kann zentral im Subflow umgesetzt und an mehreren Stellen verwendet werden.
Möchten wir beispielsweise einen einzelnen Datensatz manuell über ein Formular hinzufügen, können wir denselben Subflow erneut nutzen, ohne die Logik doppelt implementieren zu müssen.

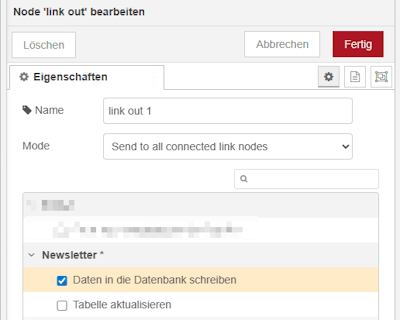
CSV-Daten in der SQLite Datenbank speichern
Der Flow zum Speichern der Daten in der SQLite-Datenbank ist bewusst ausgelagert. Dadurch bleibt der Hauptflow übersichtlich und die Logik kann bei Bedarf an anderer Stelle wiederverwendet werden.
Wie bereits erwähnt, ermöglicht dieser Aufbau eine flexible Nutzung, sodass der gleiche Flow beispielsweise auch für das manuelle Hinzufügen von Datensätzen eingesetzt werden kann.

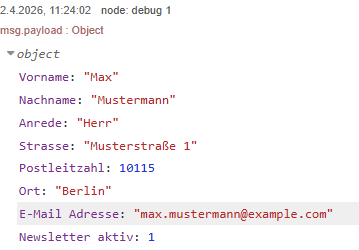
Schritt 1 – Daten empfangen aus einem vorherigen Flow
Die Link-In-Node dient als Einstiegspunkt in den Subflow für das Einfügen neuer Datensätze. Der übergebene msg.payload enthält dabei alle benötigten Informationen eines Datensatzes, sodass dieser direkt für das Erstellen des SQL-Statements verwendet werden kann.

Schritt 2 – INSERT INTO Statement erstellen
Für das Einfügen der Daten in die Datenbank wird ein INSERT INTO Statement benötigt. Dieses erzeugen wir dynamisch in einer Function-Node.
Dabei werden die einzelnen Werte aus dem msg.payload entnommen und an die entsprechenden Stellen im SQL-Statement eingesetzt. Auf diese Weise wird für jeden Datensatz ein passender Insert-Befehl erzeugt, der anschließend an die SQLite-Node übergeben werden kann.
let vorname = msg.payload.Vorname;
let nachname = msg.payload.Nachname;
let anrede = msg.payload.Anrede;
let strasse = msg.payload.Strasse;
let postleitzahl = msg.payload.Postleitzahl;
let ort = msg.payload.Ort;
let email = msg.payload["E-Mail Adresse"];
let active = msg.payload["Newsletter aktiv"];
msg.topic = `
INSERT INTO personen (vorname, nachname,anrede, strasse, postleitzahl, ort, email, newsletter_active)
VALUES ('${vorname}', '${nachname}', '${anrede}', '${strasse}', '${postleitzahl}', '${ort}', '${email}', ${active});
`;
return msg;
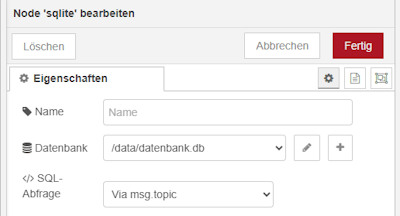
Schritt 3 – SQLite Node für die Datenbank verbindung
Die SQLite-Datenbank liegt in meinem Fall im Verzeichnis _data innerhalb des Docker-Containers und trägt den Namen datenbank.db. Wie diese Datenbank angelegt und in Node-RED eingebunden wird, habe ich bereits im Beitrag „Node-RED mit Docker – SQLite Datenbank anbinden und erste Abfragen“ ausführlich beschrieben.
Wichtig bei der SQLite-Node ist, dass sie auf das Feld msg.topic hört. Das bedeutet, dass unser zuvor erzeugtes SQL-Statement nicht in msg.payload, sondern in msg.topic geschrieben werden muss, damit es von der Node korrekt ausgeführt werden kann.

Schritt 4 – Starten des Subflows zum aktualisieren der Tabelle
Sobald ein Datensatz erfolgreich in die Datenbank geschrieben wurde, soll die Tabelle im Dashboard aktualisiert werden, damit die neuen Daten direkt sichtbar sind.
Auch dieser Ablauf ist in einen separaten Flow ausgelagert. Dadurch bleibt die Struktur übersichtlich und die Aktualisierung kann bei Bedarf von verschiedenen Stellen im System ausgelöst werden.
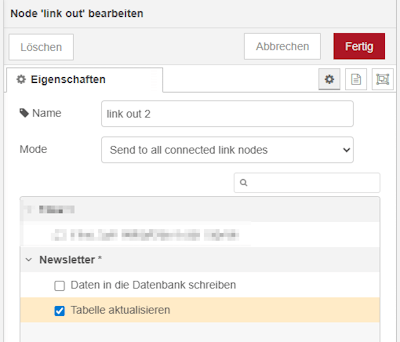
Flow zum aktualisieren der Tabelle
Der Flow zum aktualisieren der Tabelle hat zwei Eingänge, zum einen ein manueller Start damit die Daten initial geladen werden und von außen via Link In Node.

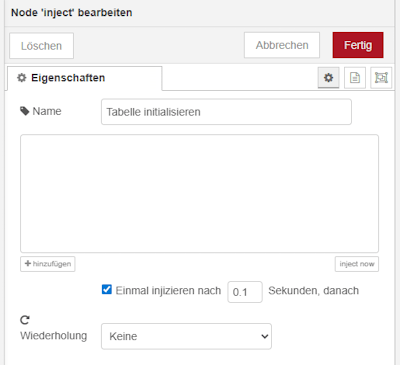
Schritt 1 – automatisches Starten des Flows
Der Flow zum Aktualisieren der Tabelle im Dashboard verfügt über einen Eingang, der beim Deploy des Flows einmalig ausgelöst wird. Dadurch werden die vorhandenen Daten direkt beim Start geladen und im Dashboard angezeigt.
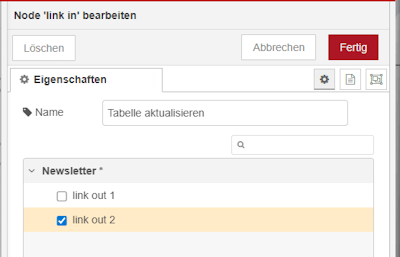
Schritt 2 – starten des Flows von einem anderen
Der zweite Eingang besteht aus einer Link-In-Node, die von außen – also aus einem anderen Flow – ausgelöst werden kann. Auf diese Weise lässt sich die Aktualisierung der Tabelle gezielt anstoßen, beispielsweise nach dem Einfügen neuer Datensätze.
Schritt 3 – Function Node für das SELECT Statement
Das SELECT Statement wird in eine eigene Function-Node ausgelagert. Dadurch kann die Abfrage unabhängig vom Start des Flows ausgeführt werden.
So lässt sich das Statement flexibel sowohl beim initialen Laden der Daten als auch bei einer späteren Aktualisierung der Tabelle wiederverwenden.
msg.topic = "SELECT * FROM personen;" return msg;
Schritt 4 – SQLite Node
Die SQLite-Node ist identisch wie zuvor konfiguriert und unterscheidet sich in diesem Schritt nicht weiter. Sie führt das übergebene SQL-Statement aus und liefert das Ergebnis zur weiteren Verarbeitung zurück.
Schritt 5 – Dashboard Tabelle mit Daten
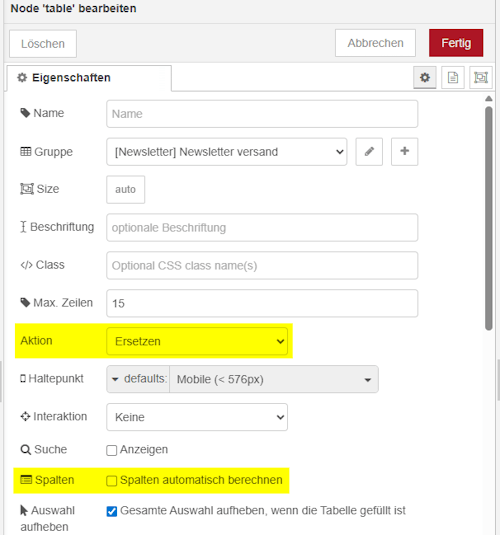
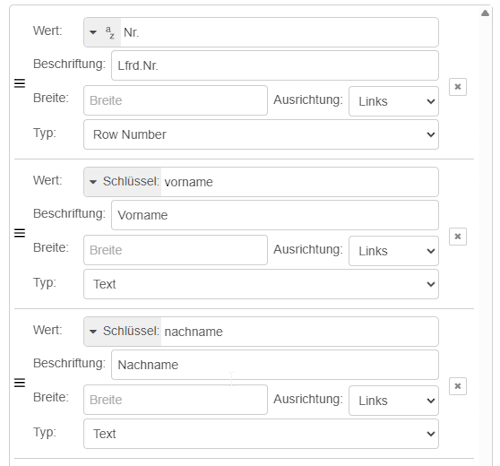
Die Daten können direkt aus der SQLite-Node in der Tabelle im Dashboard angezeigt werden. Dazu wird als Aktion „Ersetzen“ gewählt, sodass bei jeder Aktualisierung immer der aktuelle Datenbestand dargestellt wird.
Zusätzlich deaktivieren wir die Option „Spalten automatisch berechnen“. Dadurch behalten wir die volle Kontrolle über die Darstellung der Tabelle, müssen die Spalten allerdings manuell konfigurieren.

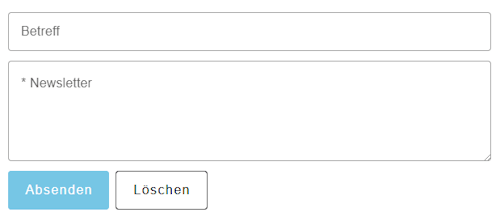
Formular zum absenden eines Newsletters
Für den Newsletter wird ein eigenes Formular im Dashboard bereitgestellt. Dieses besteht aus zwei Feldern:
- Betreff der E-Mail
- einem großen Eingabefeld für das Newsletter-Template
Im Template können Platzhalter verwendet werden, um den Newsletter später zu personalisieren. In diesem Beispiel nutzen wir folgende Platzhalter:
{{Anrede}}{{Nachname}}
Diese werden im weiteren Verlauf des Flows automatisch durch die entsprechenden Werte aus der Datenbank ersetzt. Dadurch erhält jeder Empfänger eine individuell angepasste Nachricht, ohne dass mehrere Varianten des Newsletters erstellt werden müssen.

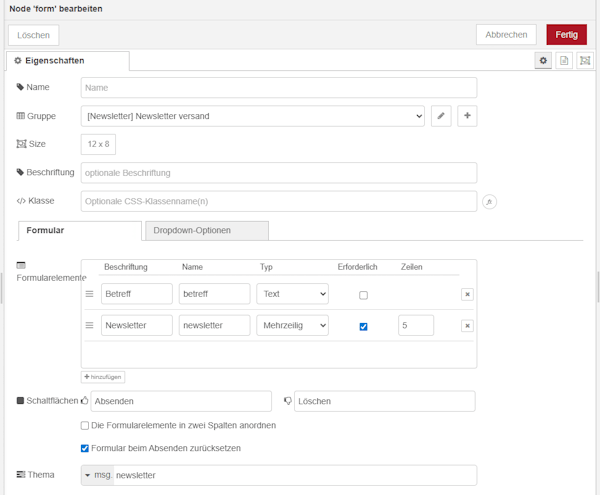
Schritt 1 – Formular für das Template des Newsletters
Das Formular besteht aus zwei Feldern, wobei das Eingabefeld für den Newsletter als Pflichtfeld (Required) definiert ist. Zusätzlich wird dieses Feld als mehrzeiliges Textfeld konfiguriert, sodass auch längere Inhalte problemlos eingegeben werden können.

Schritt 2 – Function Node mit SQL Statement
Die Function-Node enthält das SQL-Statement zum Selektieren der Daten aus der Tabelle personen. Dabei werden ausschließlich Datensätze berücksichtigt, bei denen das Feld newsletter_active auf 1 gesetzt ist.
So stellen wir sicher, dass der Newsletter nur an Empfänger versendet wird, die diesen auch aktiv abonniert haben.
msg.topic = "SELECT * FROM personen WHERE newsletter_active = 1;" return msg;
Schritt 3 – SQLite Datenbank konfigurieren
Die SQLite-Node ist identisch wie zuvor konfiguriert und unterscheidet sich in diesem Schritt nicht weiter. Sie führt das übergebene SQL-Statement aus und liefert das Ergebnis zur weiteren Verarbeitung zurück.
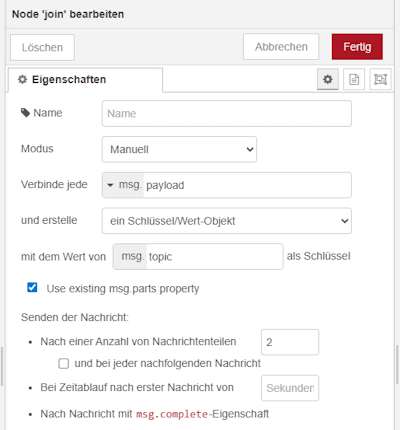
Schritt 4 – Verknüpfen der Payloads zu einem
Da wir in diesem Schritt mit zwei unterschiedlichen Datenquellen arbeiten – zum einen dem Ergebnis der Datenbankabfrage und zum anderen den Daten aus dem Formular – müssen wir diese zusammenführen. Andernfalls würde beim Weiterleiten der Nachricht jeweils eines der beiden msg.payload-Felder überschrieben werden.
Um dies zu vermeiden, nutzen wir die Join-Node. Diese ermöglicht es, mehrere Nachrichten zu einer gemeinsamen Struktur zusammenzuführen.
Dabei werden die Inhalte aus msg.payload beider Eingänge kombiniert, sodass im weiteren Verlauf sowohl die Empfängerdaten aus der Datenbank als auch das Newsletter-Template aus dem Formular gleichzeitig zur Verfügung stehen.

Schritt 5 – Daten aus dem Payload umlagern
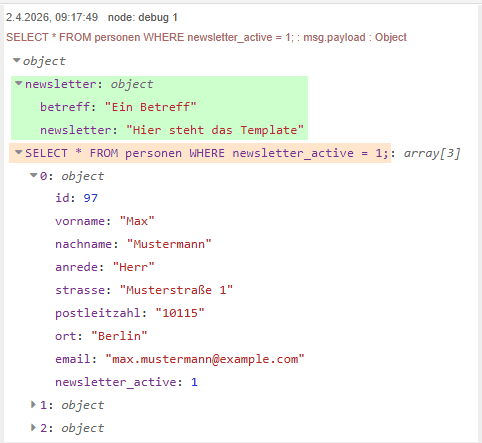
Nach dem Zusammenführen der Daten liegt nun ein gemeinsames Objekt vor. Dieses enthält zum einen die Formulardaten unter dem Schlüssel newsletter und zum anderen die Ergebnisse der Datenbankabfrage unter einem Schlüssel, der dem SQL-Statement entspricht.
Da dieser Schlüssel für die weitere Verarbeitung unpraktisch und wenig aussagekräftig ist, strukturieren wir die Daten in einer Function-Node um.
Dabei benennen wir die Daten gezielt um, sodass eine klar verständliche Struktur entsteht – beispielsweise mit den Feldern recipients für die Empfängerliste und newsletter für die Formulardaten.
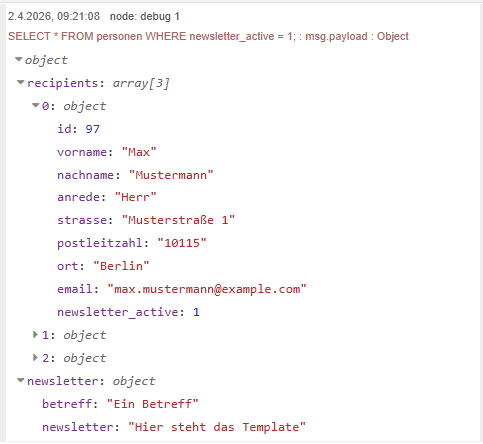
let data = msg.payload;
msg.payload = {
recipients: data["SELECT * FROM personen WHERE newsletter_active = 1;"],
newsletter: data.newsletter
};
return msg;
Anschließend liegen die Daten in einer klar strukturierten und sinnvoll benannten Form vor. Dadurch ist im weiteren Verlauf des Flows jederzeit nachvollziehbar, welche Informationen in welchem Feld enthalten sind und wofür diese verwendet werden.
Schritt 6 – E-Mail erstellen
Die E-Mail-Node erwartet ein fest definiertes Datenformat. Dieses lässt sich am einfachsten über eine Function-Node erzeugen.
Dabei werden die benötigten Felder wie folgt befüllt:
msg.to→ E-Mail-Adresse des Empfängersmsg.topic→ Betreff der E-Mailmsg.payload→ Inhalt des Newsletters
Bevor die E-Mail erzeugt wird, werden zunächst die Platzhalter im Template durch die Werte des aktuellen Datensatzes ersetzt. So entsteht für jeden Empfänger eine individuell personalisierte Nachricht.
let recipients = msg.payload.recipients || [];
let template = msg.payload.newsletter.newsletter || "";
let messages = [];
for (let user of recipients) {
let text = template
.replace(/{{Anrede}}/g, user.anrede || "")
.replace(/{{Nachname}}/g, user.nachname || "");
messages.push({
to: user.email,
topic: msg.payload.newsletter.betreff,
payload: text
});
}
return [messages];
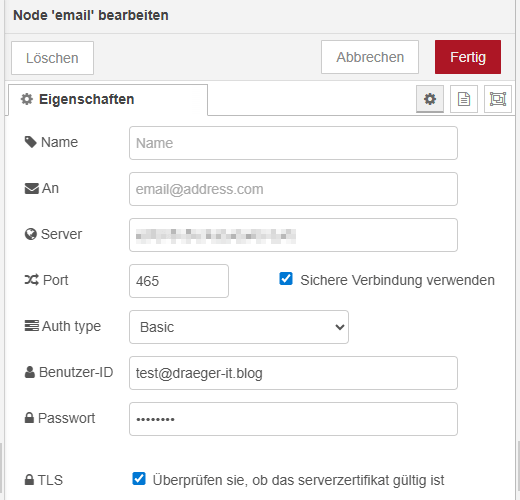
Schritt 7 – E-Mail absenden
Damit E-Mails erfolgreich versendet werden können, muss in der E-Mail-Node ein entsprechender Mail-Provider (SMTP-Server) konfiguriert werden.
Dazu werden die Zugangsdaten des Postausgangsservers hinterlegt, wie beispielsweise Serveradresse, Port sowie Benutzername und Passwort. Erst mit diesen Informationen ist Node-RED in der Lage, E-Mails tatsächlich zu versenden.

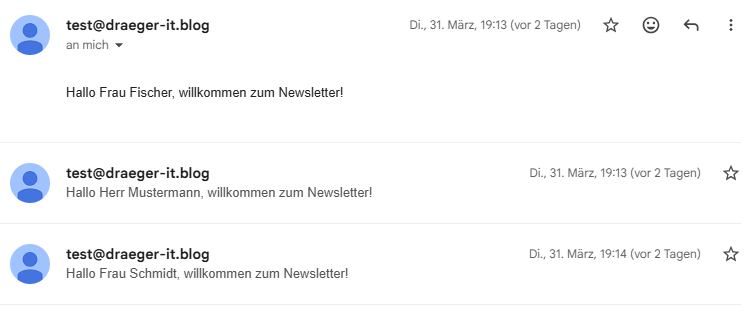
In meinem Fall habe ich das Feld „to“ auf meine Gmail Adresse gesetzt und erhalte pro Datensatz eine Mail. Im echten einsatz erhält natürlich jeder in sein Postkasten eine Mail.
Hinweis zur Fehlerbehandlung
Der hier gezeigte Flow bildet den sogenannten Happy Path ab – wir gehen also davon aus, dass alle Schritte reibungslos und ohne Fehler durchlaufen.
In der Praxis ist das jedoch nicht immer der Fall. Systeme wie der Mail-Provider, die Datenbank oder auch die CSV-Datei können Fehler liefern oder nicht wie erwartet reagieren. Eine fehlende Verbindung, ungültige Daten oder ein fehlerhaftes Format können dazu führen, dass der Flow unterbrochen wird oder falsche Ergebnisse liefert.
Daher sollte man sich in produktiven Anwendungen nicht blind darauf verlassen, dass alle angebundenen Systeme zuverlässig funktionieren. Eine saubere Fehlerbehandlung, beispielsweise durch zusätzliche Prüfungen, Catch-Nodes oder Logging, ist hier unbedingt zu empfehlen.
Fazit
Mit Node-RED lässt sich mit überschaubarem Aufwand ein kompletter Newsletter-Workflow umsetzen – von der Verarbeitung einer CSV-Datei über die Speicherung in einer Datenbank bis hin zum automatisierten Versand personalisierter E-Mails.
Besonders hervorzuheben ist dabei der visuelle Ansatz: Durch das Zusammenspiel von Nodes und Flows entsteht eine Lösung, die auch ohne tiefgehende Programmierkenntnisse verständlich und flexibel erweiterbar ist. Gleichzeitig zeigt dieses Beispiel, dass sich mit Node-RED nicht nur einfache Automatisierungen, sondern auch komplexere Anwendungsfälle sauber abbilden lassen.
Durch die Trennung in einzelne Subflows bleibt der Aufbau übersichtlich und wiederverwendbar. So können einzelne Komponenten – wie der Datenimport oder die Datenbankanbindung – auch in anderen Projekten weiterverwendet werden.
Natürlich bildet dieser Beitrag bewusst den Happy Path ab. Für den produktiven Einsatz sollten zusätzliche Aspekte wie Fehlerbehandlung, Validierung der Daten sowie Sicherheitsmechanismen (z. B. für den Newsletter-Versand) berücksichtigt werden.
Letzte Aktualisierung am: 27. April 2026
