Wie du Node-RED in einem Docker-Container startest, habe ich dir bereits im Beitrag „Node-RED mit Docker installieren – Schritt für Schritt“ gezeigt.
Nun gehen wir einen Schritt weiter und binden eine Datenbank an, damit wir die im Flow gesammelten Daten dauerhaft speichern können.

Gerade im Zusammenspiel node-red sqlite docker ist SQLite eine ideale Lösung für den Einstieg.
Der große Vorteil: SQLite benötigt keinen eigenen Server, sondern speichert alle Daten in einer einzigen Datei. Diese Datei können wir einfach in einem eingebundenen Docker-Volume ablegen und behalten unsere Daten auch nach einem Neustart des Containers.
Damit eignet sich SQLite perfekt für:
- Logging von Sensordaten
- Zwischenspeichern von API-Daten
- einfache IoT-Projekte (z. B. mit Shelly oder ESP32)
In diesem Beitrag zeige ich dir Schritt für Schritt, wie du eine SQLite-Datenbank in Node-RED einbindest und erste SQL-Abfragen ausführst.
Warum SQLite für Node-RED ideal ist
Wenn du mit Node-RED arbeitest, möchtest du Daten häufig nicht nur kurzfristig im Flow verarbeiten, sondern auch dauerhaft speichern. Genau hier kommt eine Datenbank ins Spiel.
Für den Einstieg ist SQLite besonders gut geeignet, da sie im Vergleich zu klassischen Datenbanksystemen wie MySQL oder PostgreSQL deutlich einfacher aufgebaut ist.
Der größte Vorteil: SQLite benötigt keinen eigenen Server.
Alle Daten werden in einer einzigen Datei gespeichert, die direkt im Dateisystem liegt. In unserem Fall bedeutet das, dass wir die Datenbank einfach im Docker-Volume von Node-RED ablegen können – zum Beispiel im Verzeichnis /data.
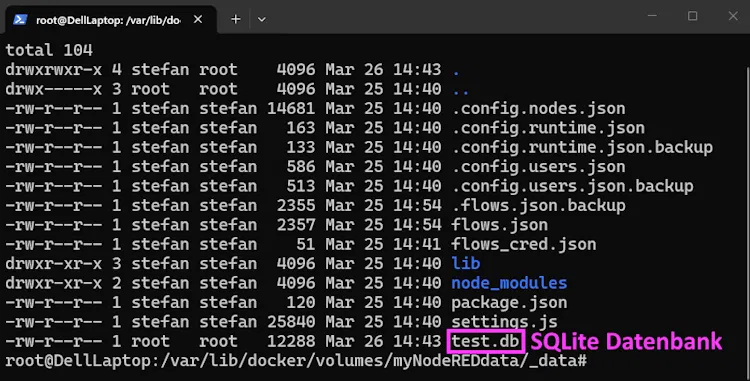
Das bringt mehrere Vorteile mit sich:
- Einfache Einrichtung
Keine zusätzliche Installation oder Konfiguration eines Datenbankservers notwendig - Perfekt für Docker geeignet
Die Datenbank ist nur eine Datei und kann problemlos über ein Volume persistent gespeichert werden - Ideal für kleine bis mittlere Projekte
z. B. Logging von Sensordaten, API-Daten oder einfache Auswertungen - Geringer Ressourcenverbrauch
SQLite ist sehr leichtgewichtig und läuft problemlos auch auf einem Raspberry Pi
Gerade im Zusammenspiel Node-RED SQLite Docker ergibt sich damit eine sehr schlanke und gleichzeitig leistungsfähige Lösung, um Daten aus deinen Flows zu speichern und später weiterzuverarbeiten.
Für größere Projekte mit vielen gleichzeitigen Zugriffen oder komplexen Abfragen kann später immer noch auf Systeme wie MySQL oder PostgreSQL gewechselt werden. Für den Einstieg und viele IoT-Anwendungen ist SQLite jedoch mehr als ausreichend.
SQLite Nodes in Node-RED installieren
Damit wir eine SQLite-Datenbank in Node-RED verwenden können, benötigen wir zunächst die passenden Nodes. Diese lassen sich ganz einfach über die integrierte Paketverwaltung nachinstallieren.
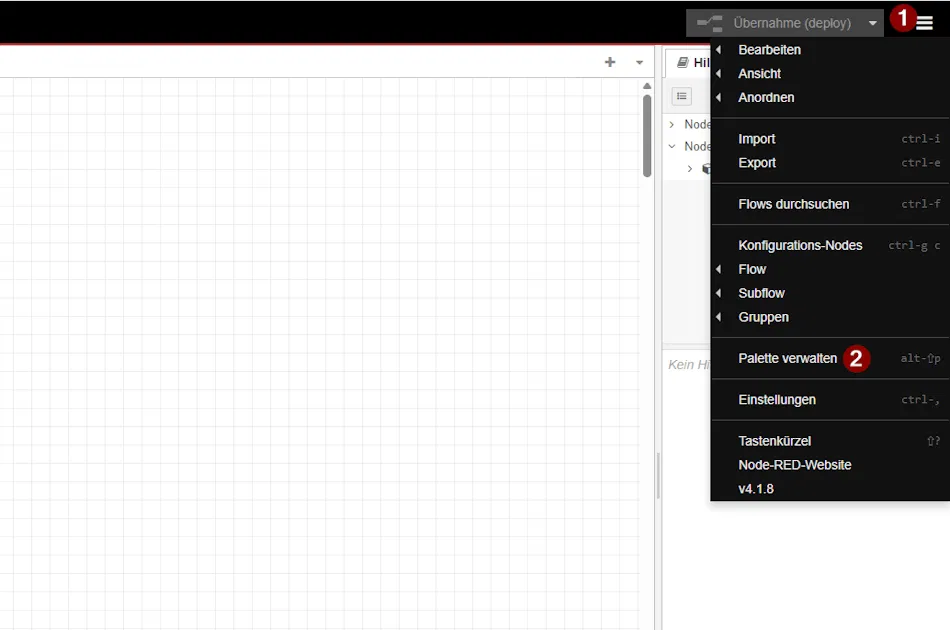
Öffne dazu im Node-RED Editor das Menü oben rechts und gehe auf:
👉 Menü → Palette verwalten → Reiter „Installieren“
Im Suchfeld gibst du anschließend sqlite ein. In der Ergebnisliste erscheint das Paket:
👉 node-red-node-sqlite
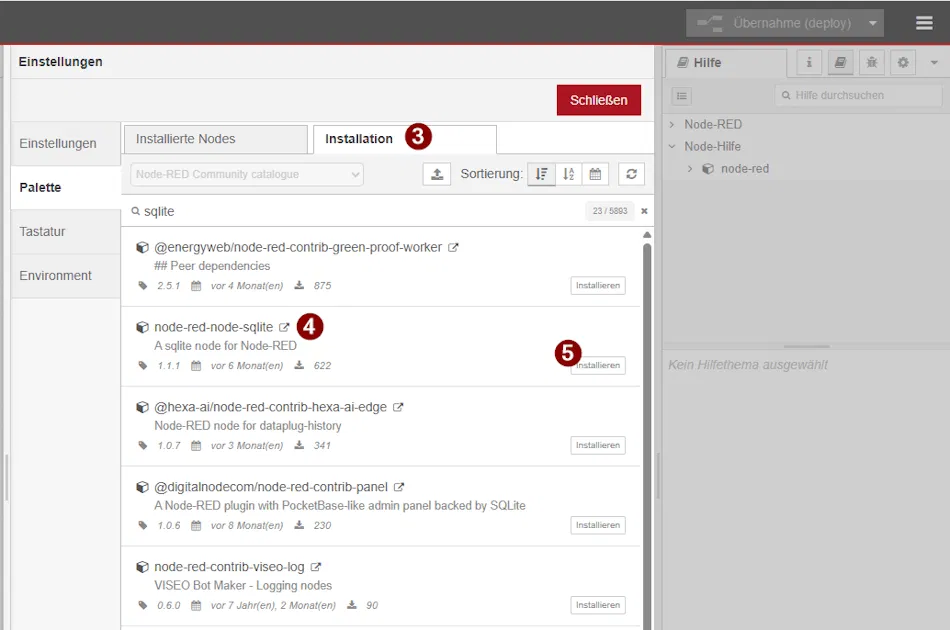
Dieses Paket stellt dir die notwendigen Nodes zur Verfügung, um SQL-Abfragen direkt innerhalb deiner Flows auszuführen.
Klicke auf Installieren und warte einen Moment, bis die Installation abgeschlossen ist. In der Regel ist kein Neustart erforderlich – die neuen Nodes stehen sofort im linken Bereich (Palette) zur Verfügung.
Nach der erfolgreichen Installation findest du die SQLite Node unter den Storage-Nodes und kannst sie per Drag & Drop in deinen Flow ziehen.
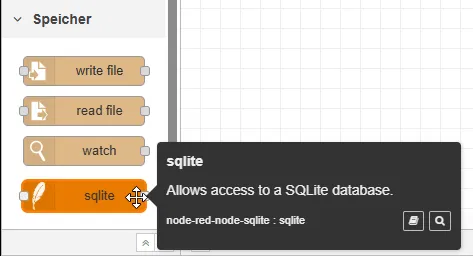
Datenbank im Container anlegen und einbinden
Für dieses Beispiel gehen wir bewusst einen einfachen und direkten Weg, um schnell eine funktionierende SQLite-Datenbank zu erhalten.
Da unser Node-RED Container ein Docker-Volume verwendet, liegt dieses auf dem Host-System im Verzeichnis:
/var/lib/docker/volumes/<volume_name>/_data/In meinem Fall lautet der Pfad:
sudo -i
cd /var/lib/docker/volumes/stefan_node_red_data/_data/Hier können wir direkt unsere Datenbankdatei anlegen:
sqlite3 datenbank.dbAnschließend erstellen wir direkt eine erste Tabelle:
CREATE TABLE IF NOT EXISTS personen (
id INTEGER PRIMARY KEY AUTOINCREMENT,
vorname TEXT NOT NULL,
nachname TEXT NOT NULL,
strasse TEXT,
plz TEXT,
ort TEXT
);
Danach verlassen wir die SQLite-Konsole mit:
.quitHinweis: Dieser Ansatz ist bewusst einfach gehalten und eignet sich besonders gut für Tests und kleinere Projekte. Alternativ könnte man auch direkt im Container arbeiten oder ein eigenes Docker-Image erstellen – für unseren Einstieg ist das jedoch nicht zwingend notwendig.
Setzen der Rechte für die Datenbank
Wenn du die SQLite-Datenbank manuell im Docker-Volume angelegt hast, kann es passieren, dass Node-RED später nicht in die Datenbank schreiben kann.
Typische Fehlermeldung:
SQLITE_READONLY: attempt to write a readonly databaseDie Ursache liegt in den Dateirechten:
Die Datenbankdatei wird häufig als root erstellt, während Node-RED im Container mit einem anderen Benutzer läuft.
Rechte im Container anpassen
Um das Problem zu beheben, wechseln wir zunächst als root in den Container:
docker exec -it --user root nodered bash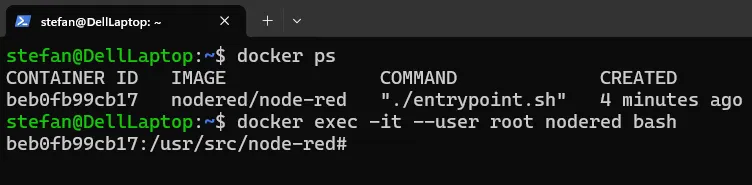
Dann setzen wir die richtigen Rechte für die Datenbankdatei und das Verzeichnis:
cd /data
chown 1000:1000 datenbank.db
chown 1000:1000 .
chmod 664 datenbank.db
chmod 755 .
exitIn meinem Fall läuft der Node-RED Docker-Container mit dem „normalen“ Benutzer, der beim Einrichten des Linux-Systems erstellt wurde. Dieser Benutzer hat in der Regel die UID 1000.
👉 Daher setzen wir den Besitzer der Datei und des Verzeichnisses ebenfalls auf diese UID, sodass Node-RED Schreibzugriff auf die SQLite-Datenbank erhält.
Warum ist das notwendig?
SQLite benötigt Schreibrechte auf:
- die Datenbankdatei selbst
- das Verzeichnis, in dem die Datei liegt
Nur wenn beide korrekt gesetzt sind, kann Node-RED Daten speichern.
Datum und Uhrzeit per SQL abfragen
Nachdem wir nun die SQLite Node installiert und unsere Datenbank angelegt haben, erstellen wir im nächsten Schritt unseren ersten einfachen Flow in Node-RED.
Ziel ist es, eine erste SQL-Abfrage auszuführen und das Ergebnis im Debug-Tab anzuzeigen.
Minimaler Test-Flow
Für diesen ersten Test benötigen wir lediglich drei Nodes:
- Inject Node → startet den Flow und enthält das SQL-Statement
- SQLite Node → führt die Abfrage aus
- Debug Node → zeigt das Ergebnis an

Inject Node konfigurieren
In der Inject Node hinterlegen wir direkt unser SQL-Statement im Feld msg.topic:
SELECT date('now');👉 Wichtig: Die SQLite Node erwartet das SQL-Statement im Feld msg.topic.
SQLite Node konfigurieren
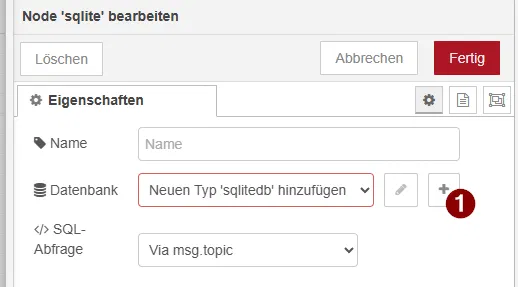
Damit die SQLite Node auf unsere Datenbank zugreifen kann, muss diese einmalig konfiguriert werden.
- SQLite Node öffnen
- Auf das Plus-Symbol (+) neben „Datenbank“ klicken
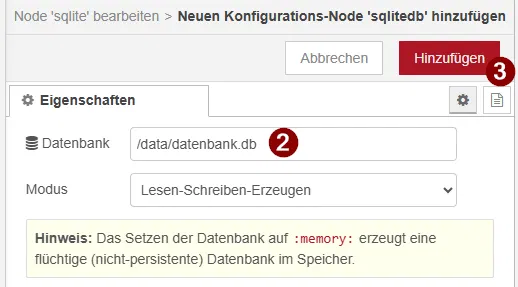
- Pfad zur Datenbank eintragen: /data/datenbank.db
- Mit „Hinzufügen“ und anschließend „Fertig“ bestätigen
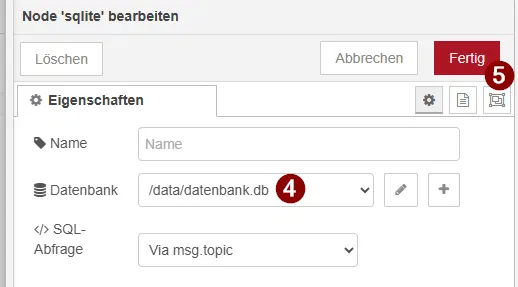
👉 Die SQLite Node ist nun einsatzbereit und verarbeitet SQL-Statements aus msg.topic.
Debug Node
Die Debug Node muss nicht weiter konfiguriert werden.
Standardmäßig lauscht sie bereits auf das Feld:
msg.payload
👉 Genau dort liefert die SQLite Node auch das Ergebnis der SQL-Abfrage.
Daten in SQLite speichern
Nachdem wir erfolgreich eine erste SQL-Abfrage ausgeführt haben, wollen wir nun Daten in unsere Tabelle personen schreiben.
Dazu erstellen wir einen einfachen Flow mit einer zusätzlichen Function Node welche uns zufallsdaten erzeugt.

Function Node zum Erzeugen von Zufallsdaten
Die Daten für die Tabelle personen könnten natürlich auch aus einem Formular im Dashboard stammen.
Der Einfachheit halber verwenden wir hier jedoch eine Function Node, die aus einer vordefinierten Liste zufällige Werte auswählt und daraus einen Datensatz erzeugt.
const vornamen = ["Max", "Anna", "Peter", "Laura", "Stefan", "Julia", "Thomas", "Sophie"];
const nachnamen = ["Mustermann", "Müller", "Schmidt", "Meier", "Schulz", "Becker", "Hoffmann", "Klein"];
const strassen = ["Hauptstraße 1", "Bahnhofstraße 12", "Gartenweg 7", "Bergstraße 22", "Mühlenweg 5"];
const plzOrte = [
{ plz: "38364", ort: "Schöningen" },
{ plz: "38100", ort: "Braunschweig" },
{ plz: "38440", ort: "Wolfsburg" },
{ plz: "38820", ort: "Halberstadt" },
{ plz: "39104", ort: "Magdeburg" }
];
function zufallEintrag(arr) {
return arr[Math.floor(Math.random() * arr.length)];
}
const vorname = zufallEintrag(vornamen);
const nachname = zufallEintrag(nachnamen);
const strasse = zufallEintrag(strassen);
const plzOrt = zufallEintrag(plzOrte);
msg.topic = `
INSERT INTO personen (vorname, nachname, strasse, plz, ort)
VALUES ('${vorname}', '${nachname}', '${strasse}', '${plzOrt.plz}', '${plzOrt.ort}');
`;
return msg;
Dieser Ansatz ist bewusst simpel gehalten und eignet sich hervorragend für erste Tests.
Für produktive Anwendungen – etwa mit Benutzereingaben oder externen Datenquellen – stößt diese Methode jedoch schnell an ihre Grenzen.
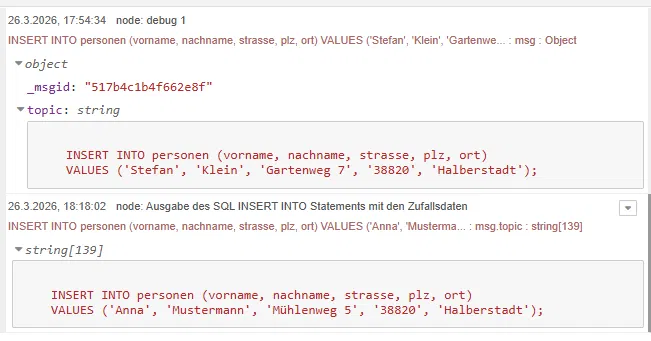
👉 Für unseren Einstieg ist sie jedoch vollkommen ausreichend, um die Funktionalität der Datenbank zu testen und erste Datensätze zu erzeugen.
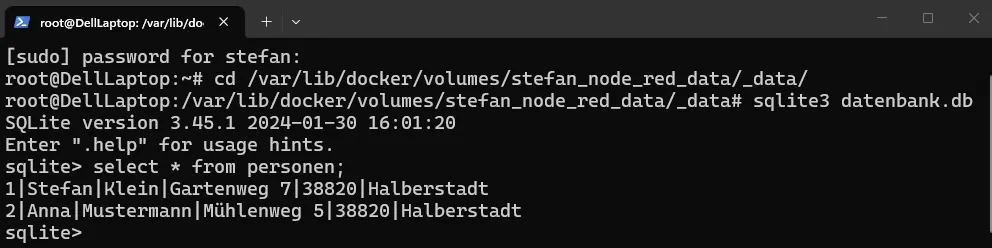
Einfaches Dashboard für die Tabelle personen
Nachdem wir nun die Tabelle personen in der Datenbank angelegt haben, erstellen wir als Nächstes ein einfaches Dashboard, über das neue Datensätze bequem erfasst werden können.
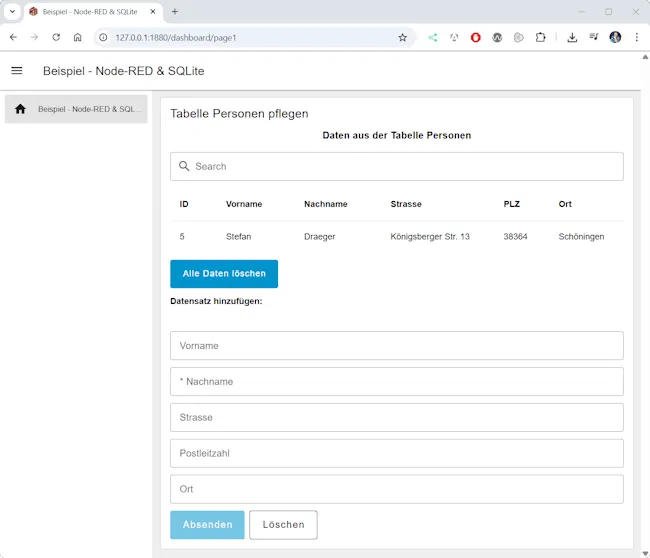
Das Ziel ist dabei bewusst einfach gehalten:
Wir möchten neue Personen über eine kleine Eingabemaske anlegen und die Daten direkt in unserer SQLite-Datenbank speichern.
Für dieses erste Beispiel konzentrieren wir uns ausschließlich auf das Hinzufügen neuer Einträge.
Das Bearbeiten oder Löschen vorhandener Datensätze würde den Flow deutlich komplexer machen und wird deshalb in einem separaten Beitrag behandelt.
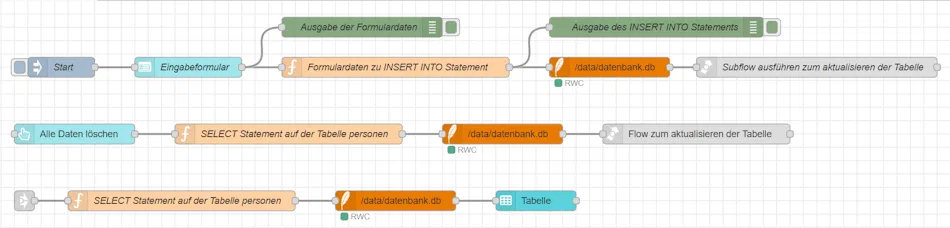
Flow zum speichern von Daten in der Datenbank
Der Flow zum Speichern der Daten in der Datenbank wird einmalig gestartet und stellt über das Dashboard ein Eingabeformular bereit. Die eingegebenen Daten werden anschließend in einer Function-Node zu einem INSERT INTO-Statement verarbeitet und danach in die Datenbank geschrieben.

Das Eingabeformular lässt sich über die Form-Node recht einfach konfigurieren. Hier definieren wir die einzelnen Felder mit Namen, die beim Absenden an die Function-Node übergeben und dort weiterverarbeitet werden.
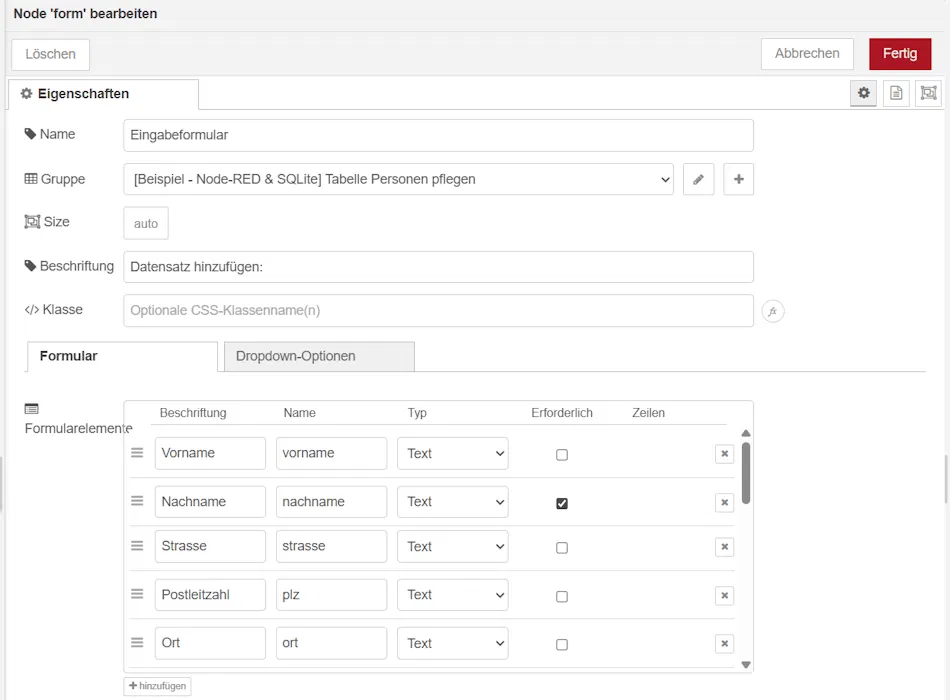
let vorname = msg.payload.vorname;
let nachname = msg.payload.nachname;
let strasse = msg.payload.strasse;
let postleitzahl = msg.payload.plz;
let ort = msg.payload.ort;
msg.topic = `
INSERT INTO personen (vorname, nachname, strasse, plz, ort)
VALUES ('${vorname}', '${nachname}', '${strasse}', '${postleitzahl}', '${ort}');
`;
return msg;
Die Formulardaten befinden sich im Feld msg.payload und können dort direkt ausgelesen werden.
In diesem einfachen Beispiel verzichten wir bewusst auf eine Validierung oder Prüfung auf doppelte Einträge. Die Werte werden lediglich entnommen und im INSERT INTO-Statement an die entsprechenden Stellen eingesetzt.
Am Ende des Flows wird der Prozess zum Aktualisieren der Daten angestoßen, sodass die Tabelle den neu hinzugefügten Datensatz direkt anzeigt.

Flow zum lesen der Daten aus der Datenbank und anzeigen in einer Tabelle
Der Flow zum Aktualisieren der Tabelle mit den Daten aus der Tabelle personen verfügt über zwei Eingänge: Zum einen wird er automatisch gestartet, zum anderen kann er von anderen Flows aus angestoßen werden.
Im Anschluss folgt eine Function-Node, die das SELECT-Statement erstellt und über msg.topic an die SQLite-Node übergibt.

Die Function-Node schreibt lediglich das SELECT-Statement in das Feld msg.topic.
Alternativ könnte man dieses auch über eine Inject-Node realisieren. Allerdings würde das Statement dann fehlen, wenn der Flow von einem anderen Flow aus gestartet wird.
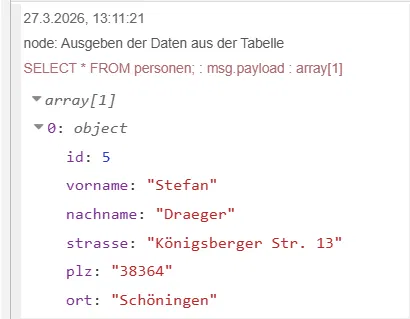
msg.topic = "SELECT * FROM personen;"; return msg;
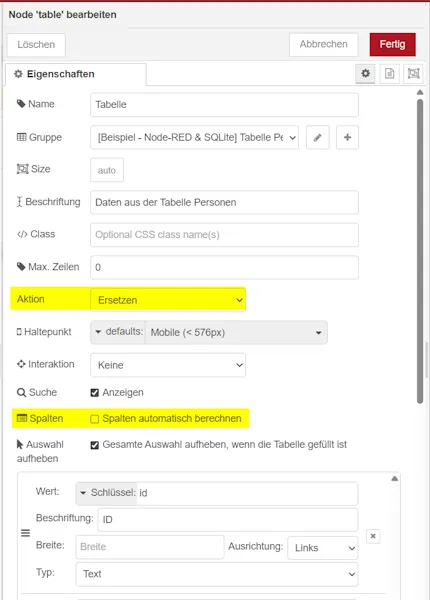
In der Konfiguration der Table Node legen wir zunächst fest das neue Wert die vorhandenen ersetzen, sowie die Spalten NICHT automatisch erkannt werden sollen.
Daraus folgt jedoch das wir im unteren Bereich dann die Spalten manuell anlegen müssen. Hier können wir uns aus einer zuvor angelegten Debug Node der Felder bedienen welche wir anlegen müssen.
Flow zum löschen aller Datensätze
Da wir derzeit lediglich nur mit Testdaten arbeiten reicht ein knopf zum löschen aller Daten. Dabei ist zu beachten das der Index der Tabelle nicht zurück gesetzt wird d.h. dieser wird erstmal noch fortgeführt.

Das Statement wird wie zuvor auch von einer Function Node bereitgestellt.
msg.topic = "DELETE FROM personen;"; return msg;
Am Ende starten wir wieder den Flow zum laden der Daten der Tabelle wobei hier einfach die Tabelle geleert wird.
Fazit & Ausblick
Mit diesem einfachen Dashboard haben wir die Grundlage geschaffen, neue Personen komfortabel in unserer Tabelle personen zu erfassen.
Gerade im Zusammenspiel Node-RED SQLite Docker zeigt sich, wie schnell sich eine funktionierende Oberfläche zur Datenerfassung umsetzen lässt – ganz ohne aufwendige Webentwicklung.
Damit steht bereits ein kleiner, aber sehr praktischer Baustein für eigene Anwendungen bereit. In weiteren Ausbaustufen könnte man das Dashboard später noch um Bearbeiten, Löschen oder zusätzliche Funktionen erweitern.
Außerdem bietet sich die Tabelle als ideale Basis für weitere Praxisbeispiele an. So könnte man in einem späteren Beitrag zum Beispiel zeigen, wie sich diese Daten nutzen lassen, um einen einfachen Newsletter-Versand umzusetzen.
Letzte Aktualisierung am: 30. März 2026
