Lange Zeit galt für Googlebot eine Obergrenze von etwa 15 MB pro HTML-Dokument. Inhalte, die darüber hinausgingen, wurden beim Crawling nicht mehr berücksichtigt. Inzwischen wurde dieses Limit deutlich reduziert: Google verarbeitet nur noch die ersten 2 MB eines HTML-Dokuments.

Für große Webseiten kann das gravierende Folgen haben. Wird diese Grenze überschritten, bricht Google das Parsen des HTML-Codes an dieser Stelle ab. Inhalte, die danach im Dokument stehen, werden nicht mehr berücksichtigt und können somit auch nicht indexiert werden.
Wichtig zu verstehen ist dabei:
Die Begrenzung bezieht sich ausschließlich auf das HTML-Dokument selbst. Ressourcen wie Bilder, Videos, CSS- oder JavaScript-Dateien werden separat geladen und zählen nicht zu diesem Limit. Befinden sich jedoch Inhalte oder wichtige Metadaten erst nach der 2-MB-Marke im HTML-Code, bleiben sie für Google unsichtbar.
Gerade bei WordPress-Seiten mit vielen Plugins, eingebetteten Daten oder umfangreichen Inline-Skripten kann die HTML-Größe schnell anwachsen. Deshalb lohnt es sich, regelmäßig zu prüfen, wie groß das tatsächlich ausgelieferte HTML-Dokument ist.
In diesem Beitrag zeige ich dir, wie du die HTML-Größe deiner Seiten automatisiert prüfst und frühzeitig erkennst, ob deine Inhalte vollständig von Google erfasst werden können.
Warum die automatisierte Prüfung sinnvoll ist
Eine einzelne Seite manuell im Browser zu prüfen, ist schnell erledigt. Doch bei einem Blog mit dutzenden oder sogar hunderten Beiträgen wird diese Methode schnell unübersichtlich und zeitaufwendig.
Eine automatisierte Prüfung bietet hier entscheidende Vorteile:
✓ Schnelle Analyse großer Websites
Alle Beiträge werden automatisch geprüft – unabhängig davon, ob es 20 oder 2.000 Seiten sind.
✓ Früherkennung von Indexierungsproblemen
Du erkennst sofort, welche Seiten das 2-MB-Limit überschreiten und möglicherweise unvollständig von Google erfasst werden.
✓ Objektive und reproduzierbare Ergebnisse
Statt Schätzungen oder Einzelprüfungen erhältst du messbare Werte in einer übersichtlichen Tabelle.
✓ Zeitersparnis bei zukünftigen Optimierungen
Nach Theme-Updates, Plugin-Installationen oder Designänderungen kannst du schnell überprüfen, ob sich die HTML-Größe verändert hat.
✓ Grundlage für gezielte Optimierungen
Große HTML-Dokumente entstehen häufig durch Inline-CSS, JSON-Daten, Page-Builder oder Tracking-Skripte. Die Analyse hilft dir, die größten Einflussfaktoren gezielt zu identifizieren.
Gerade bei WordPress-Seiten, die im Laufe der Zeit wachsen und durch Plugins erweitert werden, ist eine regelmäßige automatisierte Prüfung ein sinnvoller Bestandteil der technischen SEO-Wartung.
Messen statt raten: So prüfst du deine Seiten
Bevor wir mit einer Optimierung beginnen können, müssen wir zunächst messen. Nur wenn wir die tatsächliche Größe unserer HTML-Dokumente kennen, lässt sich beurteilen, ob Handlungsbedarf besteht.
Dafür habe ich ein kleines Python-Script erstellt, das automatisch die Sitemap einliest und anschließend durch alle enthaltenen Beiträge navigiert, um deren HTML-Größe zu ermitteln.
Die Sitemap ist dabei nicht nur eine praktische Übersicht aller Inhalte deiner Website, sondern auch eine zentrale Anlaufstelle für Suchmaschinen wie Google. Sie dient dem Googlebot als Einstiegspunkt für das Crawling und eignet sich daher ideal als Grundlage für unsere Analyse.
Wie wird am einfachsten gemessen?
Wenn man nur die HTML Datei laden möchte so kann man sich einem einfachen curl in der PowerShell bedienen.
curl.exe -L "<URL>" -o page.htmlDer Befehl lädt nun die HTML Seite in die Datei page.html und legt diese auf der Festplatte ab. Diese Datei entspricht dem HTML-Dokument, das der Googlebot abruft.
PS C:\Users\stefa> curl.exe -L "<URL>" -o page.html
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 293k 0 293k 0 0 1040k 0 --:--:-- --:--:-- --:--:-- 1057k
PS C:\Users\stefa>Automatisiertes messen mit Python
Wenn man viele Seiten hat so kann der Vorgang über curl schon sehr aufwändig werden, hierfür habe ich ein Python Skript erstellt welches einfach diesen vorgang automatisiert und die Daten erhebt. Die Daten werden dazu in eine CSV Datei geschrieben welche später in zbsp. Excel weiterverarbeitet werden kann.
Quellcode
#!/usr/bin/env python3
from __future__ import annotations
import csv
import hashlib
import shutil
import tempfile
import time
from dataclasses import dataclass
from pathlib import Path
from typing import List, Tuple
from urllib.parse import urlparse
import requests
import xml.etree.ElementTree as ET
SITEMAP_INDEX_URL = "https://draeger-it.blog/sitemap_index.xml"
OUT_CSV = "html_report.csv"
TIMEOUT_SEC = 30
DELAY_SEC = 0.05
# Wenn True, wird das Temp-Verzeichnis am Ende gelöscht
CLEANUP_TEMP_DIR = False
HEADERS = {
"User-Agent": "HTMLSizeAuditBot/1.0 (+https://draeger-it.blog/)",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
# requests entpackt gzip automatisch -> wir speichern die unkomprimierten HTML-Bytes
"Accept-Encoding": "gzip",
}
@dataclass
class Row:
url: str
lastmod: str
status: int
final_url: str
content_type: str
file_path: str
size_bytes: int
size_kb: float
lines: int
error: str
def is_http_url(u: str) -> bool:
try:
p = urlparse(u)
return p.scheme in ("http", "https") and bool(p.netloc)
except Exception:
return False
def fetch_xml(session: requests.Session, url: str) -> bytes:
r = session.get(url, headers=HEADERS, timeout=TIMEOUT_SEC)
r.raise_for_status()
return r.content
def parse_sitemap_index(session: requests.Session, sitemap_index_url: str) -> List[str]:
xml_bytes = fetch_xml(session, sitemap_index_url)
root = ET.fromstring(xml_bytes)
# sitemapindex -> <sitemap><loc>...</loc></sitemap>
locs = []
for loc in root.findall(".//{*}loc"):
if loc.text:
u = loc.text.strip()
if is_http_url(u):
locs.append(u)
return locs
def parse_urlset(session: requests.Session, sitemap_url: str) -> List[Tuple[str, str]]:
"""
Returns list of (url, lastmod). lastmod can be empty.
"""
xml_bytes = fetch_xml(session, sitemap_url)
root = ET.fromstring(xml_bytes)
out: List[Tuple[str, str]] = []
for url_node in root.findall(".//{*}url"):
loc_node = url_node.find("{*}loc")
lastmod_node = url_node.find("{*}lastmod")
if loc_node is None or not loc_node.text:
continue
loc = loc_node.text.strip()
lastmod = lastmod_node.text.strip() if (lastmod_node is not None and lastmod_node.text) else ""
if is_http_url(loc):
out.append((loc, lastmod))
return out
def collect_all_pages(session: requests.Session) -> List[Tuple[str, str]]:
"""
Supports sitemap_index.xml that points to multiple sitemaps (urlsets).
"""
sitemap_urls = parse_sitemap_index(session, SITEMAP_INDEX_URL)
all_pages: List[Tuple[str, str]] = []
for sm in sitemap_urls:
try:
all_pages.extend(parse_urlset(session, sm))
except Exception as e:
print(f"[WARN] Konnte Sitemap nicht lesen: {sm} ({e})")
# Deduplicate while preserving order
seen = set()
unique: List[Tuple[str, str]] = []
for u, lm in all_pages:
if u not in seen:
unique.append((u, lm))
seen.add(u)
return unique
def safe_filename(url: str) -> str:
"""
Stable filename per URL (avoid Windows path issues).
"""
h = hashlib.sha1(url.encode("utf-8")).hexdigest()[:12]
# optional: add a short readable part
path = urlparse(url).path.strip("/").replace("/", "_")
path = path[:60] if path else "root"
return f"{path}__{h}.html"
def download_html_to_file(session: requests.Session, url: str, target_file: Path) -> Tuple[requests.Response, str]:
"""
Downloads a URL and stores the HTML response bytes into target_file.
Returns (response, error_msg). error_msg empty if ok.
"""
try:
r = session.get(url, headers=HEADERS, timeout=TIMEOUT_SEC, allow_redirects=True)
except Exception as e:
return None, f"request_error: {e}"
# Content-Type check (optional but useful)
ct = (r.headers.get("Content-Type") or "").lower()
if r.status_code != 200:
return r, f"http_status: {r.status_code}"
if "text/html" not in ct and "application/xhtml" not in ct:
# still write content for debugging if you want; here we skip writing
return r, f"not_html: {ct}"
# Save uncompressed HTML bytes (requests already decompressed gzip)
try:
target_file.write_bytes(r.content)
except Exception as e:
return r, f"file_write_error: {e}"
return r, ""
def count_lines_from_bytes(data: bytes, encoding_hint: str | None = None) -> int:
"""
Counts lines in HTML (best-effort decode).
"""
# Try utf-8 first; fallback to latin-1 to avoid decode errors
for enc in filter(None, [encoding_hint, "utf-8", "cp1252", "latin-1"]):
try:
text = data.decode(enc, errors="strict")
return len(text.splitlines()) or 1
except Exception:
continue
# Last resort
text = data.decode("utf-8", errors="ignore")
return len(text.splitlines()) or 1
def main() -> None:
session = requests.Session()
temp_dir = Path(tempfile.mkdtemp(prefix="html_audit_"))
print(f"[INFO] Temp-Verzeichnis: {temp_dir}")
pages = collect_all_pages(session)
print(f"[INFO] Gefundene URLs: {len(pages)}")
rows: List[Row] = []
for i, (url, lastmod) in enumerate(pages, start=1):
fname = safe_filename(url)
fpath = temp_dir / fname
t0 = time.time()
resp, err = download_html_to_file(session, url, fpath)
elapsed_ms = int((time.time() - t0) * 1000)
status = resp.status_code if resp is not None else 0
final_url = resp.url if resp is not None else ""
content_type = resp.headers.get("Content-Type", "") if resp is not None else ""
size_bytes = 0
lines = 0
if not err and fpath.exists():
data = fpath.read_bytes()
size_bytes = len(data)
# encoding hint from response (if present)
encoding_hint = resp.encoding if (resp is not None and resp.encoding) else None
lines = count_lines_from_bytes(data, encoding_hint=encoding_hint)
rows.append(
Row(
url=url,
lastmod=lastmod,
status=status,
final_url=final_url,
content_type=content_type,
file_path=str(fpath),
size_bytes=size_bytes,
size_kb=round(size_bytes / 1024, 2),
lines=lines,
error=err,
)
)
print(f"[{i}/{len(pages)}] {status} {url} -> {rows[-1].size_kb} KB, {rows[-1].lines} lines ({elapsed_ms} ms)"
+ (f" ERROR: {err}" if err else ""))
time.sleep(DELAY_SEC)
# Write CSV
with open(OUT_CSV, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f, delimiter=";")
writer.writerow([
"url",
"lastmod",
"status",
"final_url",
"content_type",
"file_path",
"size_bytes",
"size_kb",
"lines",
"error",
])
for r in rows:
writer.writerow([
r.url,
r.lastmod,
r.status,
r.final_url,
r.content_type,
r.file_path,
r.size_bytes,
r.size_kb,
r.lines,
r.error,
])
print(f"[DONE] CSV gespeichert: {OUT_CSV}")
if CLEANUP_TEMP_DIR:
shutil.rmtree(temp_dir, ignore_errors=True)
print("[INFO] Temp-Verzeichnis gelöscht.")
else:
print("[INFO] Temp-Verzeichnis bleibt erhalten (CLEANUP_TEMP_DIR=False).")
if __name__ == "__main__":
main()
In meinem Fall sieht es recht positiv aus:
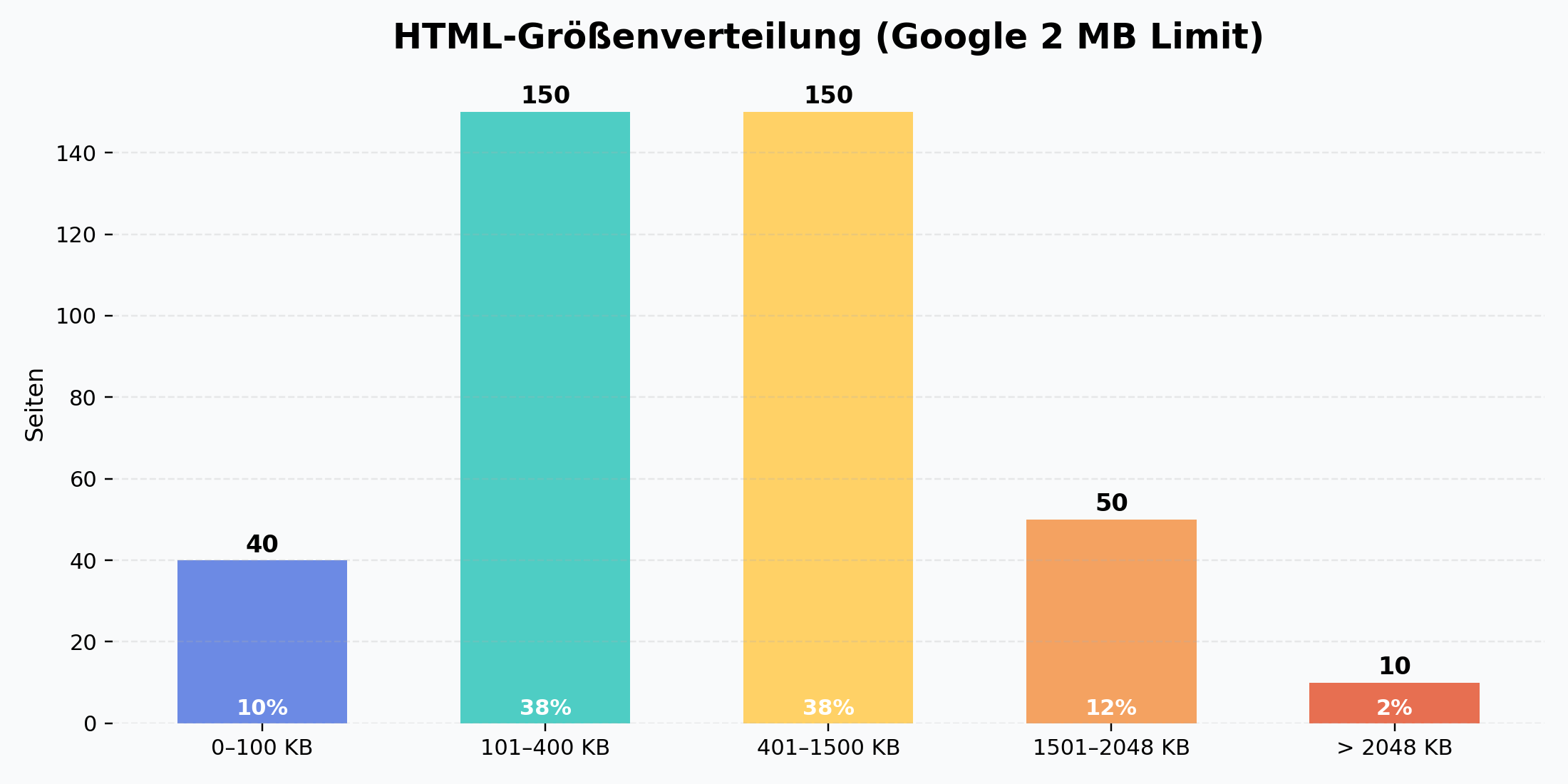
HTML Größenverteilung
Gesamtseiten: 3296
Range 1 (0–100 KB) 4 Seiten (0.1%)
Range 2 (101–400 KB) 3292 Seiten (99.9%)
Range 3 (401–1500 KB) 0 Seiten (0.0%)
Range 4 (1501–2048 KB) 0 Seiten (0.0%)
Range 5 (> 2048 KB) 0 Seiten (0.0%)Fazit
Das 2-MB-Limit für HTML-Dokumente ist kein theoretisches Detail, sondern kann direkte Auswirkungen auf die Sichtbarkeit deiner Inhalte in den Suchergebnissen haben. Wird diese Grenze überschritten, verarbeitet Google nur den ersten Teil des Dokuments – Inhalte, strukturierte Daten oder wichtige Metainformationen danach bleiben unberücksichtigt.
Gerade bei gewachsenen WordPress-Seiten mit vielen Plugins, Inline-Skripten oder Page-Buildern kann die HTML-Größe unbemerkt anwachsen. Deshalb lohnt es sich, die tatsächliche Dokumentgröße regelmäßig zu prüfen.
Während sich einzelne Seiten schnell manuell kontrollieren lassen, bietet eine automatisierte Analyse deutliche Vorteile: Du erhältst reproduzierbare Messwerte, erkennst kritische Seiten sofort und kannst gezielt optimieren, bevor Indexierungsprobleme entstehen.
Die gute Nachricht: In den meisten Fällen reicht es bereits aus, unnötige Inline-Inhalte zu reduzieren, Scripts auszulagern oder überladene Plugins zu überprüfen, um die HTML-Größe deutlich zu verringern.
Mit den hier gezeigten Methoden und dem Python-Script hast du ein einfaches Werkzeug an der Hand, um deine Website technisch im Blick zu behalten und sicherzustellen, dass Google deine Inhalte vollständig erfassen kann.
Weitere SEO- und Optimierungstipps
Die HTML-Größe ist nur ein Baustein einer technisch sauberen Website. Wenn du deine Seite nachhaltig optimieren möchtest, findest du in meiner Kategorie zur Suchmaschinenoptimierung weitere praxisnahe Beiträge rund um Performance, Crawling und technische SEO:
👉 Suchmaschinenoptimierung Kategorie draeger-it.blog
Hier findest du alle Beiträge zum Thema SEO gebündelt.
Besonders hilfreich im Zusammenhang mit der HTML-Größe und Indexierung sind unter anderem:
- Technische SEO-Grundlagen – wie Suchmaschinen deine Website crawlen und interpretieren
- Performance-Optimierung für WordPress – Ladezeiten reduzieren und unnötigen Ballast entfernen
- Typische SEO-Fehler vermeiden – Probleme erkennen, bevor sie Rankings kosten
- Monitoring & Analyse deiner Website – technische Probleme frühzeitig erkennen
- Strukturierte Daten richtig einsetzen – Inhalte für Suchmaschinen verständlich aufbereiten
Eine technisch optimierte Website entsteht nicht über Nacht. Doch mit den richtigen Werkzeugen und einem klaren Verständnis der wichtigsten Einflussfaktoren kannst du Schritt für Schritt bessere Ergebnisse erzielen.
Letzte Aktualisierung am: 21. März 2026
